Le défi de l’identification des bénéficiaires #
L’écosystème de la santé rassemble plusieurs types d’acteurs : laboratoires pharmaceutiques, professionnels de santé et associations de patients. Ces acteurs entretiennent entre eux des relations financières et d’influence qui peuvent créer des conflits d’intérêt.
Pour limiter ces risques, la base Transparence Santé impose aux entreprises de la santé de déclarer publiquement les avantages et rémunérations qu’elles versent aux professionnels de santé et aux autres acteurs du secteur. Cette base de données est utilisée par le projet EurosForDocs pour analyser ces flux financiers.
Mais pour analyser précisément ces liens d’intérêt, il faut pouvoir identifier sans ambiguïté chaque bénéficiaire d’avantages ou de rémunérations. Or, la plateforme gouvernementale accorde une grande liberté aux entreprises dans la rédaction de leurs déclarations. Cette flexibilité conduit à un problème pratique : un même bénéficiaire peut être décrit de nombreuses façons différentes selon les entreprises. Il peut alors être compliqué de regrouper toutes les déclaration le concernant.
La situation idéale pour regrouper les différentes déclarations relatives à un même bénéficiaire serait la présence d’un identifiant national unique. Les professionnels de santé disposent justement d’un tel numéro : le numéro RPPS. Un ancien référentiel (le numéro ADELI) est également disponible et peut être traduit en RPPS pour la plupart des professions. Les sociétés savantes et les associations de patients peuvent être identifiées par leur numéro national d’association (RNA) ou leur numéro SIREN.
En pratique, les déclarations sont loin de respecter les standards de qualité attendus. Le taux de saisie d’un numéro SIREN ou RNA pour les personnes morales n’est que de 50%. La situation était similaire pour les professionnels de santé, mais une mise à jour de la plateforme de déclaration a permis d’augmenter le taux de déclaration à 90%.
Un des objectifs du retraitement d’EurosForDocs est de fusionner tous les comptes de bénéficiaires relatifs à une même entité physique, même en l’absence d’identifiant national. Pour cela, nous avons implémenté un système en quatre étapes :
-
Correction des identifiants incohérents. Nous corrigeons les déclarations qui ont des numéros RPPS mais pour lesquelles les noms, prénoms et profession déclarés sont incohérents par rapport aux informations de l’annuaire officiel RPPS. Cette étape est le sujet d’un article dédié.
-
Attribution d’identifiants. Nous tentons de retrouver l’identifiant manquant d’un bénéficiaire en le recherchant dans un annuaire officiel (RPPS pour les professionnels de santé, SIREN/RNA pour les personnes morales).
-
Recherche de liens directs. Lorsque l’identification dans un annuaire échoue, nous cherchons des correspondances directes entre comptes en comparant leurs informations (nom, prénom, profession, etc.).
-
Création d’entités. Un algorithme regroupe automatiquement tous les comptes qui sont reliés entre eux, directement ou par l’intermédiaire d’autres comptes pour recréer les entités physiques auxquelles ils correspondent.
Méthodes de rapprochement des comptes #
Comme mentionné dans la section précédente, la situation idéale consiste à avoir un identifiant national pour chaque compte bénéficiaire. Lorsque aucun n’est présent, nous cherchons à en retrouver grâce à différentes sources de vérité.
Réattribution des identifiants #
Les professionnels de santé constituent les cas les plus simples à traiter. L’annuaire santé (ou RPPS) liste tous les professionnels de santé exerçant en France, parfois avec différentes variantes pour leur nom, prénom ou code postal. Il inclut également pour chaque professionnel son numéro RPPS et/ou ADELI. Nous pouvons ainsi tenter d’attribuer directement un numéro RPPS aux professionnels déclarés sans aucun identifiant.
Pour chacun de ces professionnels, nous recherchons dans l’annuaire une personne avec le même nom, prénom et profession. S’il n’existe qu’un seul numéro RPPS dans l’annuaire avec ces informations (donc pas d’homonymes qui pourraient créer une ambiguïté), nous l’attribuons à ce compte.
Plusieurs variantes de cette logique sont testées pour ajuster les seuils de tolérance sur les informations considérées et tenter de contourner les problématiques d’homonymie. Par exemple, on peut tenter de jouer sur le code postal s’il est déclaré pour lever des ambiguités, ou travailler sur les sous parties d’un nom composé. Contrairement aux techniques appliquées dans cet article, on n’attribue pas un numéro RPPS à un compte si nous n’obtenons pas un matching exact pour une approche donnée. Nous choisissons donc de ne pas pouvoir traiter de simples erreurs typographiques, qui ouvriraient la porte à beaucoup trop de faux positifs. Parmis les 2 millions de comptes de professionnels déclarés sans RPPS, 60% se voient attribuer un identifiant à la fin de cette procédure.
En théorie, nous devrions pouvoir appliquer la même logique aux personnes morales grâce aux annuaires des associations et SIREN. Malheureusement, la seule information réellement utilisable est le nom de l’entité. Alors qu’on s’attend à trouver le nom exact pour une personne physique (avec parfois des problématiques de nom de jeune fille/d’épouse), un nom d’association permet de plus grandes variations sans remettre en question l’intelligibilité de la déclaration. Par exemple, dans cette étude de cas, l’Association Clinique et Thérapeutique Infantile du Val de Marne a été identifiée sous différentes mentions, allant du nom complet jusqu’à l’acronyme ACTIV en passant par des versions condensées telles que “Ass Cliniq Therap Infantil”. Une telle diversité ne permet pas d’appliquer une logique d’attribution similaire à celle des personnes physiques.
Lors de l’exploration des données, nous avons également identifié des cas particuliers. Certaines entreprises déclarent des numéros d’identification qui ne semblent pas correspondre à des référentiels nationaux, mais qui semblent être liés de manière unique à un même bénéficiaire. Nous en avons déduit que ces numéros doivent être des numéros d’identification internes. Nous utilisons alors ces numéros (par entreprise) comme des identifiants nationaux pour lier entre eux différents comptes d’une même entité.
Enfin, certains doublons de comptes résistent à toutes nos méthodes (incluant celles non encore présentées). Ces doublons sont en général identifiés par des utilisateurs durant leur explorations de certaines personnes ou associations spécifiques. Nous avons alors mis en place un système de modifications manuelles qui permet d’atttribuer des identifiants à des comptes bénéficiaires.
Lien direct entre comptes #
Une deuxième stratégie pour fusionner des comptes consiste à prouver que deux comptes bénéficiaires font référence à la même entité, même en l’absence d’identifiant. Dans le cas idéal, le premier compte possède un identifiant qui sera propagé au second. Lorsque aucun compte n’a d’identifiant, ce lien permet néanmoins de fusionner les deux comptes, en espérant qu’un autre lien direct avec un troisième compte permettra une identification ultérieure.
Professionnels de santé #
La première stratégie mise en place s’applique aux professionnels de santé. Nous cherchons à regrouper les comptes bénéficiaires qui ont le même nom, prénom, profession et code postal, mais qui peuvent être déclarés par des entreprises différentes.
Cette approche peut néanmoins produire de faux positifs, même avec l’exigence d’un code postal renseigné. Imaginons par exemple un cas où un compte sans RPPS coexiste avec deux autres comptes partageant les mêmes nom, prénom, profession et code postal, mais possédant des RPPS distincts. Dans cette situation, l’attribution du bon RPPS devient impossible. Après avoir complété les RPPS dans la mesure du possible lors des étapes précédentes, nous appliquons une contrainte supplémentaire : chaque groupe de comptes homonymes ne peut contenir qu’un seul numéro RPPS. Cette limitation réduit significativement les risques d’erreur d’attribution.
Personnes morales #
Concernant les personnes morales, la stratégie est similaire mais ne peut se baser que sur le nom de l’entité. Ici, le risque de fusionner des comptes homonymes est beaucoup plus élevé : il n’est pas rare que des entités différentes aient le même acronyme et que les entreprises ne déclarent que ce derner. Nous avons également identifié un nombre conséquent de déclarations pour lesquelles le nom du bénéficiaire est un mot-clé non indicatif: “Hôpital” par exemple.
Ces différents cas rendent important d’avoir un mécanisme de limitation des faux positifs. Comme pour les professionnels de santé, nous imposons à un groupe de bénéficiaires homonymes de ne pas avoir plus d’un seul identifiant parmi eux pour permettre aux comptes sans identifiants d’en recevoir un. De plus nous interdisons les liens entre les comptes dont les noms sont des mots non indicatifs.
Liens manuels #
Enfin, certaines études particulières effectuées par nos utilisateurs nous ont remonté des liens entre des comptes pour lesquels aucun identifiant n’est renseigné. La plupart du temps, nous essayons de leur attribuer manuellement des identifiants comme mentionné dans la section précédente.
Malheureusement, il peut être difficile d’obtenir un identifiant pour certaines entités. Par exemple, certains groupes de travail inter-entités n’ont techniquement pas d’existence légale mais reçoivent des financements pour leur activité. Même si ces financements sont sûrement attribués comptablement à des entités légales qui participent à ces groupes de travail, la déclaration ne mentionne que le groupe, qui n’aura alors pas d’identifiant. Dans ces cas particuliers, nous créons alors une nouvelle base de données de liens entre comptes qui permet de lier des comptes deux à deux.
Création des entités #
La section précédente nous a présenté plusieurs cas de figure de liens entre les comptes. Selon la qualité des déclarations, ces liens peuvent être nombreux et divers. Nous avons donc besoin d’une stratégie pour reconstituer des entités uniques et de qualité à partir de cet ensemble de comptes déclarés et des liens entre eux.
Regroupement par identifiant #
Considérons le cas le plus simple où plusieurs comptes sont reliés entre eux via un même identifiant. Nous pouvons alors regrouper tous les comptes avec le même identifiant. Par exemple, imaginons que les comptes suivants sont tous reliés au même numéro RPPS :
| id | nom | prenom | profession | rpps |
|---|---|---|---|---|
| 1 | Dupont | Christine | pharmacien | 1000 |
| 2 | Dupont | Christine | 1000 | |
| 3 | Dupont | Cristine | 1000 |
Nous cherchons à créer une entité pour cette pharmacienne qui soit la meilleure combinaison possible des informations contenues dans tous les comptes.
Ici, le nom ne pose aucun problème puisqu’il est identique partout.
Le nom final de notre entité sera donc Dupont.
Notre stratégie de déduplication nous permet d’enrichir nos données avec la profession de cette personne. En effet, les déclarations correspondant aux comptes bénéficiaires 2 et 3 n’ont pas documenté de profession. Grâce à la mise en relation de ces 3 comptes grâce au numéro RPPS, nous pouvons attribuer une profession à l’ensemble des comptes, ce qui améliorera la qualité des déclarations sans cette information.
Ce système nous permet également d’unifier certaines informations variables.
Par exemple, le compte numéro 3 a une typo sur le prénom : le h est manquant.
Il pourrait tout aussi bien renseigner une variante du prénom : nous avons des cas de Marie-Christine simplement déclarés comme Marie ou Christine.
Il y a donc naturellement une variabilité dans les données déclarées.
Nous pouvons choisir la variante la plus pertinente pour créer notre entité finale.
Ainsi, toutes les déclarations avec des informations erronnées et/ou variantes pourront être modifiées pour harmoniser toutes les déclarations liées à cette personne.
Pour permettre de relier un compte bénéficiaire à une entité, il est préférable de créer un ID pour cette entité. Il est important d’avoir un identifiant qui possède une certaine stabilité. En effet, nous avons quotidiennement de nouvelles déclarations ou des modifications. Nous souhaitons un identifiant qui ne change que peu lorsque de nouvelles déclarations sont créés, pour que les utilisateurs puissent facilement retrouver les bénéficiaires qui les intéressent d’un jour à l’autre.
La solution que nous avons choisie est d’utiliser le plus petit ID présent parmi les comptes dupliqués. L’ajout de nouveaux comptes à la liste des dupliqués ne changera pas l’ID de référence pour le groupe. La mise à jour de déclarations ou l’amélioration de la logique de fusion peuvent changer l’ID, mais la proportion de comptes impactés sera relativement faible.
Impact des relations variées #
La logique de regroupement par identifiant unique devient plus complexe lorsque plusieurs types de liens coexistent entre les comptes.
Considérons l’exemple suivant : les comptes 0 et 1 partagent le même numéro RPPS, le compte 2 est lié au compte 1 via un identifiant interne d’entreprise, et le compte 3 est directement relié au compte 1 par une correspondance de données.
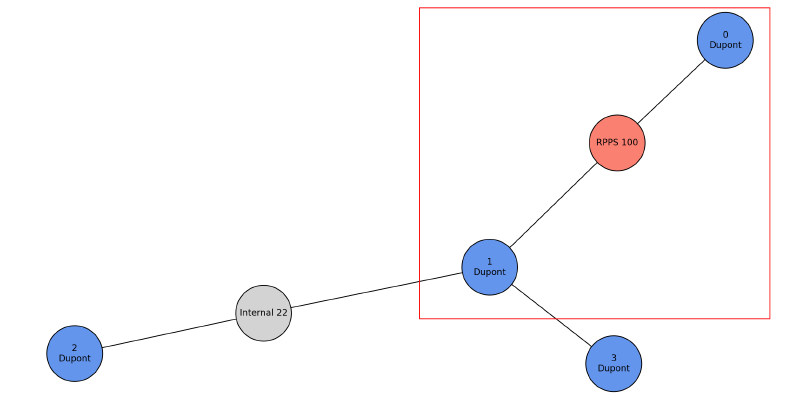
Si nous nous limitons au regroupement par RPPS (encadré rouge), nous exclurions les comptes 2 et 3 de l’entité finale, alors qu’ils correspondent au même bénéficiaire. La solution consiste à étendre le regroupement de manière récursive : tous les comptes liés à un membre du groupe initial doivent être inclus dans l’entité finale. Cette logique s’applique de manière itérative jusqu’à ce qu’aucun nouveau compte ne puisse être ajouté.
Une fois tous les comptes liés identifiés, nous appliquons la même stratégie de déduplication que précédemment pour déterminer le nom, prénom et autres caractéristiques finales de l’entité.
Regroupement des sous composants #
Cette logique itérative de devoir chercher de nouveaux comptes liés à un membre d’un groupe à travers différents types de liens est assez complexe à mettre en place lorsque l’on se place dans le contexte de données ayant la forme d’un tableau Excel; ce que nous avons fait implicitement dans cet article ainsi que les précédents parlant d’EurosForDocs. Cependant, un changement de paradigme va nous permettre d’implémenter cette logique de manière extrêmement simple. Ce paradigme est la représentation des données sous la forme d’un réseau.
Un réseau se compose d’une liste d’entités (des nœuds) qui peuvent être reliées entre elles à travers différents mécanismes. La notion de réseau est assez connue aujourd’hui à travers les réseaux sociaux, où des personnes sont reliées entre elles par des liens “d’amitié” sur Facebook ou des utilisateurs reliés à des produits et entreprises dans une base de données d’e-commerce par exemple.
Pour créer notre réseau de doublons, nous devons nous poser deux questions principales : en quoi consisteront les nœuds du réseau et quels seront les liens entre eux. Premièrement, notre réseau va contenir tous les comptes bénéficiaires comme nœuds. Cependant, nous allons aussi ajouter comme nœuds tous les identifiants présents dans la base. Nous aurons donc un ensemble de nœuds correspondant à différents SIREN, un autre ensemble pour les numéros RPPS, etc… Les identifiants internes des entreprises que nous avions mentionnés plus tôt généreront également des nœuds.
Ensuite nous allons chercher à relier ces nœuds entre eux. Toutes les règles métier détaillées plut haut vont nous permettre de lier des nœuds entre eux. La présence d’un numéro RPPS déclaré (ou retrouvé) permet de relier le nœud correspondant à ce bénéficiaire avec le nœud correspondant à son numéro RPPS. Les relations directes entre les comptes peuvent également être représentées par des liens entre leurs nœuds respectifs. C’est cette représentation qui a été utilisée dans l’exemple précédent. Une fois ce réseau créé nous obtenons quelque chose qui va ressembler à l’image suivante, mais avec près de 8 millions de nœuds et 8 millions de liens entre ces neouds.
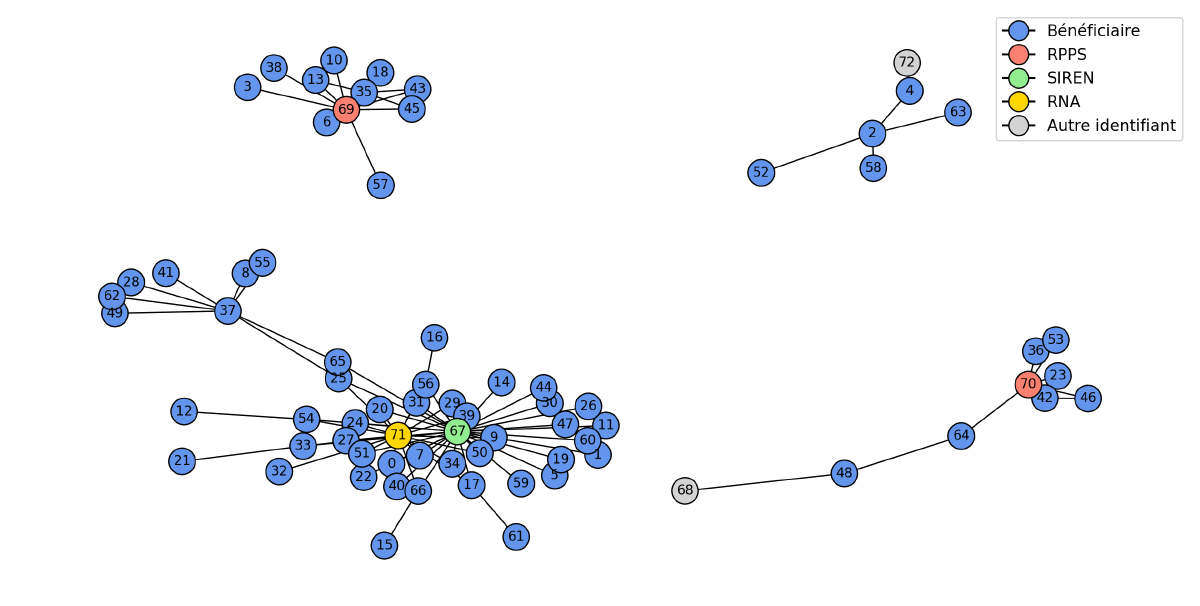
Si on regarde attentivement le réseau, on se rend compte que les nœuds sont naturellement organisés en 4 groupes. Dans chacun de ces groupes, les bénéficiaires sont reliés entre eux soit directement, soit à travers une liaison en commun avec un numéro d’identification. Le groupe en bas à gauche montre bien que la plupart des noeuds s’organisent autours d’un numéro SIREN et d’un numéro RNA, mais avec des noeuds à gauche regroupés autour du noeud 37, lui même lié au reste du group via des relations directes avec d’autres comptes bénéficiaires. Chacun de ces groupes correspond alors à l’ensemble des noeuds reliés entre eux de près ou de loin; c’est à dire à une entité finale.
Les réseaux en tant qu’objets mathématiques possèdent une vaste gamme d’algorithmes qui permettent de les explorer et d’en déduire leurs propriétés. En particulier, l’algorithme des composants connectés va explorer un réseau et répartir des nœuds dans des groupes de manière à ce qu’il soit toujours possible d’atteindre un nœud du groupe depuis un autre, éventuellement en passant par d’autres nœuds intermédiaires, en suivant les liens. Par contre, deux nœuds n’appartenant pas au même groupe ne seront pas accessibles l’un de l’autre.
Ce nouveau formalisme est alors utilisé pour extraire les groupes de comptes bénéficiaires qui permettront de créer les entités. Puisque le problème des composants connectés est relativement ancien, nous avons accès à des implémentations optimisées pour des données de type graphe. Cela rend la procédure beaucoup plus efficace qu’un code manuel; potentiellement dans un formalisme et une technologie non prévus pour ce genre de problème. Le fait de pouvoir appeler un algorithme très connu réduit aussi la quantité de code (puisque l’on peut appeler un outil dédié) et facilite la documentation. Au final, nous avions 7.1 millions de comptes bénéficiaires que nous avons pu dédupliquer en 2.1 millions d’entités.
Gestion des incohérences #
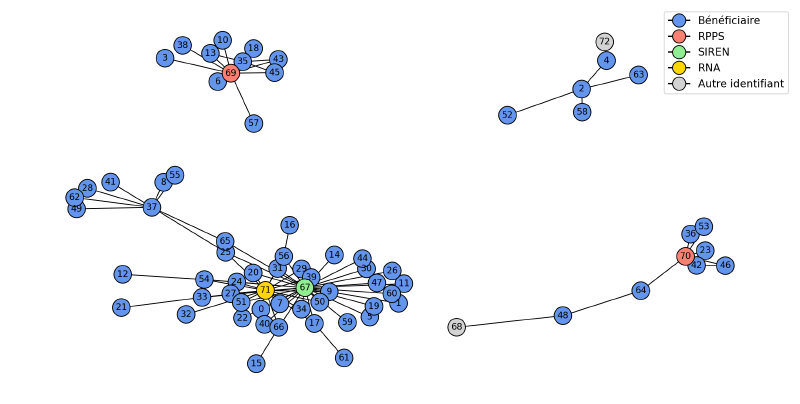
L’algorithme des composants connectés révèle un problème important : certains groupes contiennent plusieurs identifiants du même type (plusieurs RPPS ou plusieurs SIREN). Cette situation indique une erreur dans les données, car chaque identifiant devrait être unique pour une entité.
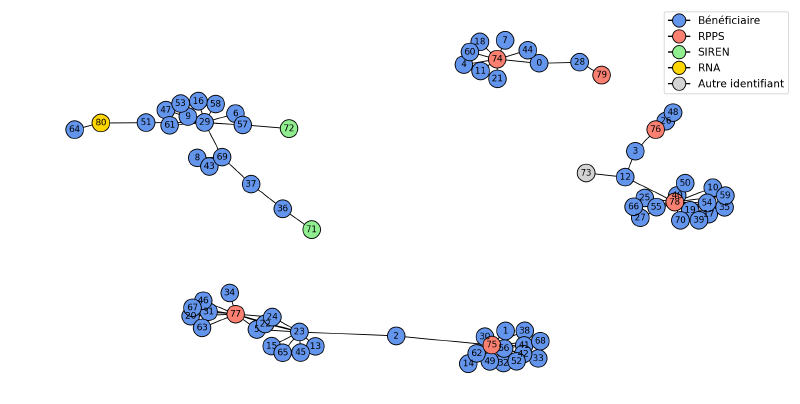
Dans l’exemple illustré, le groupe du bas contient deux numéros RPPS distincts (77 et 75), suggérant que deux entités différentes ont été incorrectement liées. Le compte bénéficiaire 2 présente probablement un lien erroné. Des situations plus complexes existent, comme le groupe de gauche où les nœuds SIREN se trouvent en périphérie de la structure.
La création d’entité grâce aux composants connectés présente deux avantages. Elle permet de regrouper efficacement les comptes liés tout en identifiant automatiquement les groupes présentant des incohérences. Pour limiter les erreurs de traitement, nous choisissons de ne pas fusionner les comptes appartenant à un groupe incohérent, mais de les marquer pour un traitement ultérieur, automatique ou manuel.
Conclusion #
La déduplication de comptes bénéficiaires de la base Transparence Santé nécessite une approche progressive combinant attribution d’identifiants, correspondances directes et regroupement algorithmique. La modélisation en graphe transforme ce problème complexe en un algorithme standard de composants connectés, permettant de traiter efficacement 7,1 millions de comptes pour obtenir 2,1 millions d’entités distinctes.
Cette méthodologie offre un cadre structuré pour l’entity resolution : commencer par les identifiants fiables, étendre avec des correspondances directes, puis utiliser la théorie des graphes pour gérer les relations multiples. La détection automatique des incohérences maintient la qualité des données tout en identifiant les cas nécessitant une intervention manuelle.