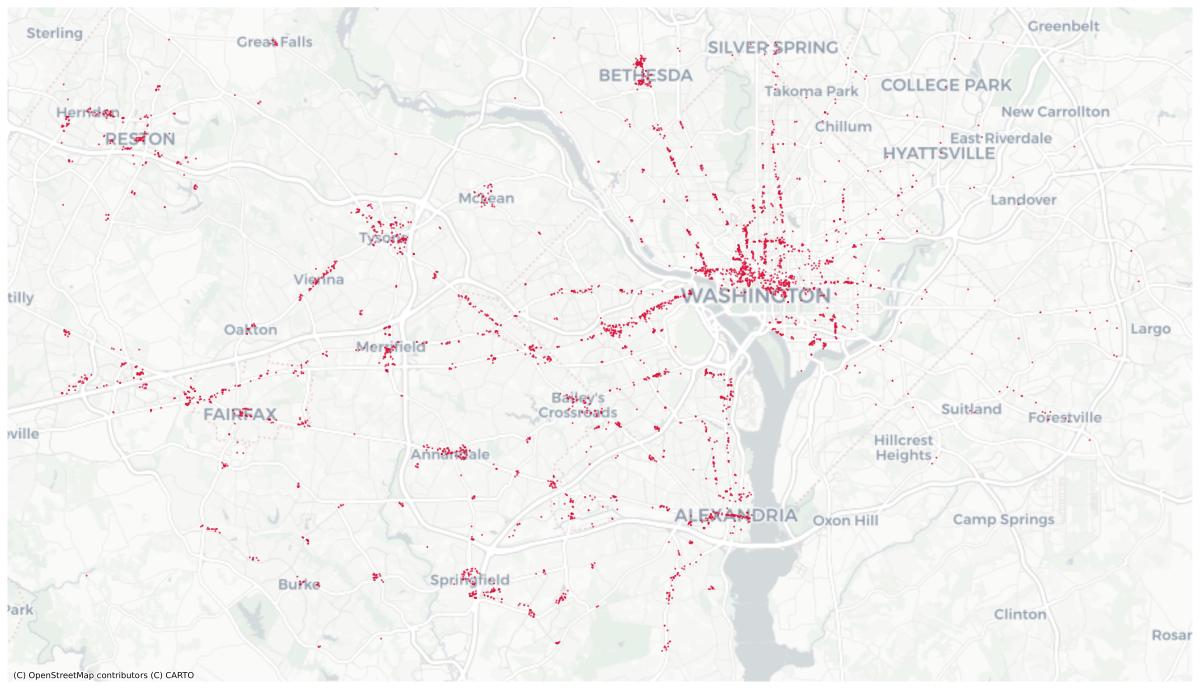
Imaginons que je sois un consultant souhaitant faire une analyse de marché de la restauration à emporter.
Je souhaite connaître pour chaque restaurant le nombre de concurrents dans un rayon de 2km.
Je peux par exemple avoir accès à des données similaires à ce dataset Kaggle, qui nous permet d’avoir accès à plus de 60k restaurants présents sur UberEats dans tous les États-Unis.
En particulier, nous avons notamment accès aux coordonnées GPS de chaque restaurant.
Cette donnée va nous permettre de calculer la distance entre deux restaurants, et donc savoir s’ils sont potentiellement concurrents.
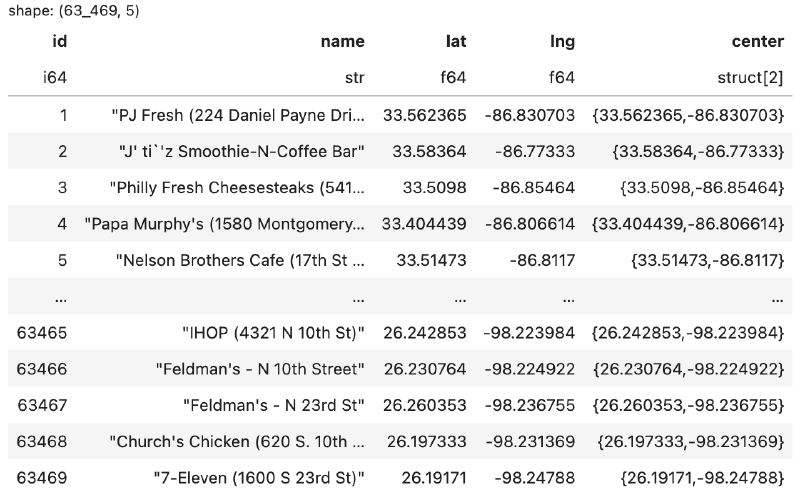
La colonne center a été ajoutée pour permettre l’utilisation en polars de la librairie polars-distance
Une méthode naïve non scalable #
Dans un monde small data, le calcul du niveau de concurrence est assez simple.
Calculer la distance entre toutes les paires de restaurants et ne garder que celles ayant une distance inférieure à 2km.
C’est ce que le code suivant implémente en polars.
Il est à noter l’utilisation de la jointure cross pour créer toutes les paires de restaurants.
def filter_by_distance(frame: pl.DataFrame, distance: float) -> pl.DataFrame:
return frame.filter(
pld.col("center").dist.haversine("center_right", unit="km") <= distance
)
def identify_neighbors(frame: pl.DataFrame, distance_treshold: float) -> pl.DataFrame:
return (
frame.join(frame, how="cross")
.filter(col("id") != col("id_right"))
.pipe(filter_by_distance, distance_treshold)
)
possible_neighbors = identify_neighbors(restaurants.head(10000), 2)
possible_neighbors.shape # (334626, 10)Cette technique a deux limitations principales.
-
Le nombre de calculs de distance à effectuer croît quadratiquement avec le nombre de restaurants. Ici avec seulement 10k restaurants (pour un dataset de 63.5k), c’est déjà 100 millions de paires qui doivent être testées. Du fait de sa lenteur (92 secondes) et de sa forte consommation de RAM, ce type d’approche peut coûter très cher sur des plateformes de cloud computing. D’ailleurs, ma machine sature en RAM lorsque je tente d’appliquer l’analyse sur les 63.5k restaurants. Enfin à partir de 66k restaurants, polars aurait levé une exception car sa version de base semble limitée à 2^32 lignes dans un DataFrame.
-
L’immense majorité des distances calculées le sont pour des paires absurdes. Par exemple, cette technique calcule toutes les paires contenant un restaurant à New York et un à Los Angeles ; restaurants qui sont de manière évidente trop éloignés les uns des autres pour être des concurrents. Dans notre cas, seules 335k paires de concurrents existent effectivement dans notre dataset, soit 0.3% de toutes les paires testées. Les calculs de distance pour ces paires représentent donc une pure perte de temps et de coût d’infrastructure.
La méthode des bloqueurs pour réduire la complexité #
La solution de ce problème est présente dans sa description. En réduisant le nombre de paires absurdes, on va pouvoir accélérer la recherche de concurrents sans perdre de données pertinentes. Il serait alors pratique de savoir avant de calculer la distance entre deux restaurants s’ils ont une chance même minime d’être concurrents.
On peut par exemple découper les États-Unis en petites zones de 0.1 degré de latitude et de longitude de côté. Cela correspond grossièrement à des zones de 10km de haut pour 5km de large. Deux restaurants qui ne sont pas dans des régions adjacentes n’ont alors aucune chance d’être concurrents. Deux restaurants dans des zones adjacentes peuvent encore être à plus de 20km l’un de l’autre. Il est donc toujours nécessaire de calculer la distance entre restaurants pour définir s’ils sont concurrents mais le nombre de combinaisons possibles est alors beaucoup plus faible.
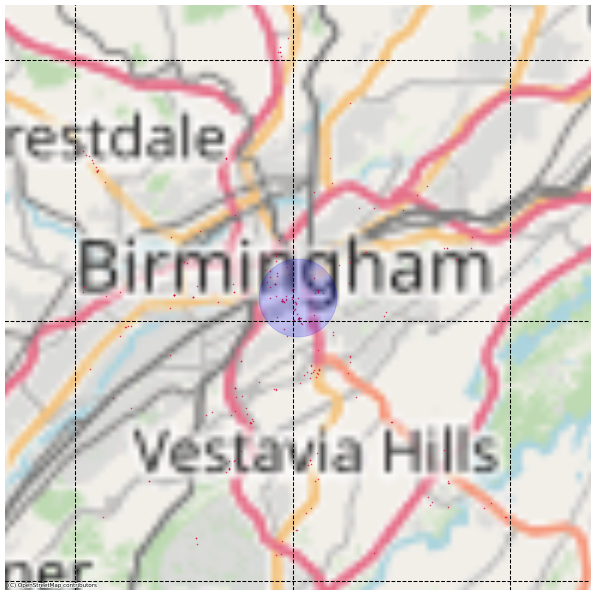
D’un point de vue technique, on peut alors remplacer une jointure cross très coûteuse par plusieurs jointures inner bien plus optimisées.
En reformattant la fonction identify_neighbors comme ci-dessous, nous réduisons le nombre de paires testées à seulement 4 millions (soit 4 % de toutes les paires possibles).
Notre dataset à 10 000 restaurants est donc traité en 207ms au lieu de 92s et on retrouve au final exactement les 334 626 restaurants concurrents.
On peut alors même traiter l’intégralité des 63.5k restaurants pour identifier 4.2 millions de paires en moins de 4s.
def add_restaurant_region(frame: pl.DataFrame) -> pl.DataFrame:
return frame.with_columns(
(col("lng") * 10).cast(pl.Int64).alias("region_lng"),
(col("lat") * 10).cast(pl.Int64).alias("region_lat"),
)
def partitionned_identify_neighbors(
frame: pl.DataFrame, distance_treshold: float
) -> pl.DataFrame:
frame = add_restaurant_region(frame)
neighbors = []
for lat_shift in range(-1, 2):
for lng_shift in range(-1, 2):
tmp = frame.with_columns(
col("region_lat") + lat_shift, col("region_lng") + lng_shift
)
joined = (
frame.join(tmp, on=["region_lat", "region_lng"])
.filter(col("id") != col("id_right"))
.drop(["region_lat", "region_lng"])
.pipe(filter_by_distance, distance_treshold)
)
neighbors.append(joined)
return pl.concat(neighbors)
partitioned = partitionned_identify_neighbors(restaurants.head(10000), 2000)
partitioned.shape # (334626, 10)Conclusion #
La jointure de table grâce à des règles métiers au lieu de colonnes d’identifiant permet une grande diversité d’applications. Cependant, ce type de jointure peut s’avérer très coûteux du fait du nombre de combinaisons possibles et qu’une part significative des calculs à effectuer n’apportent aucune valeur. Le découpage des États-Unis en petites zones a permis de se rapprocher d’une situation avec des colonnes d’identifiant. On a alors pu utiliser les optimisations liées à ce type de jointure pour mener notre analyse 500x plus vite.
C’est donc à travers une compréhension fine du problème et un peu de créativité que nous avons pu lever les blocages liés au temps de calcul de cette analyse.
Pour aller plus loin #
D’autres data scientists ont partagé leurs solutions à des problèmes similaires.
What’s in a Name? Fast Fuzzy String Matching #
Dans leur présentation au Midwest.io 2015, deux data scientists ont présenté un problème conceptuellement plus simple : identifier les noms similaires entre une liste de 10 millions et une autre de 40 000 ? Avec 400 milliards de paires à comparer, le calcul de la similarité Jaro-Winkler pour chaque paire prendrait 13 jours. À travers une compréhension profonde de cette similarité et des choix de structure de données pertinents, ils ont réduit ce calcul à 5 min.
Leur solution repose sur deux piliers :
-
Compréhension de Jaro-Winkler : Ils ont réalisé que l’on pouvait tordre la formule pour obtenir une borne supérieure basée uniquement sur les caractères partagés. En ne calculant que cette borne, ils ont pu écarter massivement et rapidement les paires non pertinentes sans jamais avoir à effectuer le calcul complet, bien plus coûteux, de la similarité.
-
Optimiser matériellement : Pour rendre ce filtrage quasi-instantané, ils ont utilisé une structure de données astucieuse : le
bitset. Chaque mot est représenté par une séquence de bits où chaque bit correspond à une lettre de l’alphabet. Si le mot contient la lettre, le bit est à 1, sinon à 0. Cette représentation permet au processeur de comparer les ensembles de lettres de deux mots en une seule instruction, offrant un gain de temps considérable.


