La restauration des employés constitue un défi logistique et RH pour les entreprises opérant 24h/24. Alors que les supermarchés, restaurants et boulangeries sont accessibles en journée, les options se raréfient la nuit pour des professions comme les contrôleurs aériens ou les employés d’hôtels. Une solution en plein essor est la mise à disposition de frigos connectés. Situés au sein de l’entreprise, ils sont régulièrement approvisionnés en produits variés (entrées, plats, desserts, boissons) pour permettre aux employés de se restaurer à toute heure.
Dans l’une de mes précédentes entreprises, Foodles, l’objectif était de se différencier sur ce marché en proposant des plats frais, préparés par des traiteurs spécialisés et renouvelés quotidiennement. À ce critère de qualité s’ajoutait une forte exigence de diversité pour les convives. Chaque frigo contenait entre six et huit recettes différentes de plats principaux, et l’intégralité du menu était renouvelée deux fois par semaine pour éviter la lassitude.
Pour les équipes internes, la création de ces menus représentait donc une tâche complexe. Il fallait d’abord sélectionner une centaine de recettes pertinentes pour une période de six semaines, puis les répartir entre les différentes demi-semaines. La difficulté principale résidait dans le respect des nombreuses règles métier qui conditionnaient la composition des menus :
-
Pour satisfaire tous les convives, il était essentiel de garantir une variété au sein de chaque menu. Celui-ci devait inclure des plats carnés et végétariens, à base de pâtes ou de légumes. Un autre aspect de la diversité à prendre en compte était la répartition équilibrée de plats d’origines diverses (asiatiques, indiens, etc.) sur l’ensemble des périodes.
-
Les plats étaient préparés quotidiennement par des traiteurs partenaires, souvent spécialisés dans certains types de recettes. Pour maintenir une relation durable avec eux, il était nécessaire d’assurer une certaine stabilité dans les volumes de commandes. Une charge de travail trop fluctuante — avec de nombreuses recettes à préparer une semaine et aucune la suivante — n’était pas soutenable pour eux. Enfin une répartition maximale des plats entre les différents fournisseurs permettait une plus grande résilience en cas d’imprévus.
Ce processus manuel peut facilement prendre plusieurs heures. Mais au delà de ce temps initial, chaque nouveau contre temps (par exemple une rupture de stock chez un partenaire) nécessite un temps non négligeable pour adapter la répartition initiale à la nouvelle situation.
L’optimisation sous contraintes : une approche algorithmique #
Pour automatiser la création de menus, le problème de répartition peut être formulé en utilisant une approche issue de la recherche opérationnelle : l’optimisation sous contraintes. Ce domaine des mathématiques appliquées fournit un cadre et des outils pour trouver la meilleure solution possible à un problème, au regard d’un objectif donné, parmi un grand nombre de possibilités.
La première étape consiste à traduire le problème métier en un modèle mathématique. Un tel modèle se compose de trois éléments clés :
-
Les variables de décision : ce sont les inconnues que l’on cherche à déterminer. Elles représentent les choix à notre disposition. Dans notre cas, il s’agit de savoir si un plat donné est assigné (ou non) à une demi-semaine spécifique.
-
Les contraintes : elles définissent les règles que toute solution doit impérativement respecter. Les contraintes traduisent les exigences métier en équations ou inéquations. Par exemple :
- Chaque demi-semaine doit contenir exactement 2 plats.
- Un plat ne peut être proposé qu’une seule fois sur toute la période.
- Deux plats étant trop similaires, c’est à dire ayants des caractéristiques (ou tags) en commun ne doivent pas être dans le même menu.
-
La fonction objectif : c’est le critère que l’on cherche à optimiser (minimiser ou maximiser). Elle quantifie la “qualité” d’une solution. Pour ce problème, un objectif peut être de simplement trouver une répartition qui respecte toutes les règles. On pourrait aussi chercher à maximiser une note de variété, ou à minimiser la répétition de certains ingrédients.
Une fois le problème formalisé avec ces trois composantes, l’étape suivante consiste à utiliser un outil pour le résoudre. C’est là qu’interviennent des algorithmes spécialisés, appelés solveurs. Un solveur est un moteur de calcul capable d’identifier efficacement les solutions les plus pertinentes et d’identifier celle qui optimise la fonction objectif, tout en respectant l’ensemble des contraintes.
Pour illustrer ce principe, prenons un exemple simple. Imaginons que nous cherchons la valeur de \(x\) qui maximise la fonction représentée par la courbe bleue ci-dessous.
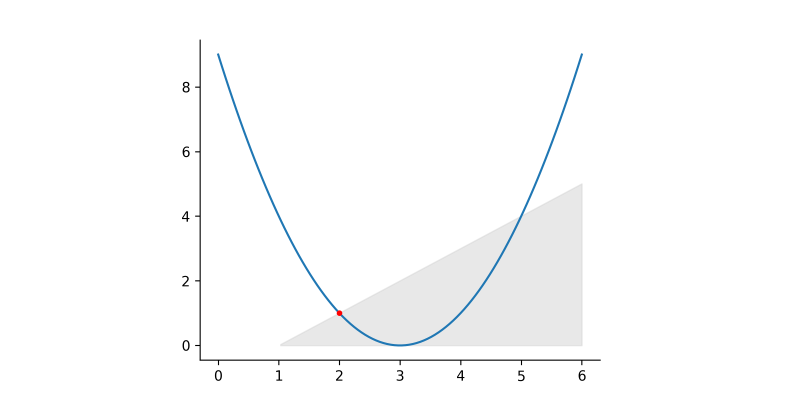
Sans aucune contrainte, la solution optimale serait \(x=3\). Cependant, si l’on impose une contrainte, par exemple que \(x-1\) ne doive pas être inférieur à \(0\), la solution optimale est ramenée à \(x=2\), car c’est la meilleure valeur qui respecte cette nouvelle règle. C’est ce type de logique qu’un solveur applique, mais à des problèmes plus vastes.
Il existe une grande variété de solveurs, chacun étant spécialisé dans un certain type de problème. Certains sont conçus pour des problèmes quadratiques avec des variables continues (des nombres flottants) et des contraintes linéaires, tandis que d’autres peuvent traiter des variables discrètes (comme des booléens) et des contraintes plus complexes.
Le choix du bon solveur et la formulation du problème dans un format qu’il comprend peuvent être complexes. Heureusement, des bibliothèques de plus haut niveau permettent de simplifier ce processus. Dans cet article, nous utiliserons la bibliothèque Python CVXPY. Elle fournit une interface intuitive pour modéliser le problème en termes de variables, de contraintes et d’objectif dans le formalisme de numpy. Elle se charge enfin d’identifier le solveur adapté et de lui soumettre le problème.
Modélisation du problème #
Pour traduire notre problème de planification en un modèle mathématique, il nous faut d’abord définir nos variables de décision. L’enjeu est de déterminer, pour chaque plat et chaque période, si le plat est assigné ou non.
Une manière courante de représenter ce type de choix est d’utiliser une matrice de décision booléenne.
Cette matrice aura les plats en lignes et les périodes en colonnes.
Une cellule contiendra la valeur 1 si le plat correspondant est sélectionné pour la période, et 0 sinon.
Pour concrétiser cette approche, commençons par définir nos données d’exemple en Python : une liste de plats avec leurs tags (caractéristiques), et une liste de périodes.
import numpy as np
import pandas as pd
meals = sorted(
[
("tagliatelles carbonara", ["porc", "viande", "pate"]),
("lasagnes bolognaise", ["boeuf", "viande", "pate"]),
("cordon bleu - petits pois", ["poulet", "viande"]),
("boulette de boeuf - purée", ["boeuf", "viande", "patate"]),
("escalope de veau patate grenaille", ["viande", "boeuf", "patate"]),
("parmentier de canard", ["viande", "patate"]),
("saumon riz", ["poisson", "riz"]),
("colin carottes", ["poisson"]),
("wok de crevettes", ["poisson", "pate"]),
("tagliatelles forestières", ["vegetarien", "pate"]),
("salade nicoise", ["vegetarien"]),
("risotto aux champignons", ["vegetarien", "riz"]),
("ratatouille riz", ["riz", "vegetarien"]),
]
)
periods = [(f"week{i}", p) for i in range(3) for p in ["start", "end"]]
repartition_template = pd.DataFrame(
# La matrice est initialisée avec des données aléatoires
# uniquement pour illustrer la structure que nous cherchons à obtenir.
(np.random.rand(len(meals), len(periods)) > 0.5).astype(np.int8),
index=[x[0] for x in meals],
columns=pd.MultiIndex.from_tuples(periods, names=["week", "week_part"]),
)| week | week0 | week1 | week2 | |||
|---|---|---|---|---|---|---|
| week_part | start | end | start | end | start | end |
| boulette de boeuf - purée | 1 | 1 | 0 | 0 | 0 | 0 |
| colin carottes | 0 | 0 | 0 | 0 | 0 | 1 |
| cordon bleu - petits pois | 0 | 0 | 1 | 1 | 1 | 0 |
| escalope de veau patate grenaille | 0 | 0 | 0 | 1 | 0 | 1 |
| lasagnes bolognaise | 1 | 1 | 0 | 0 | 0 | 0 |
| parmentier de canard | 1 | 0 | 1 | 1 | 0 | 1 |
| ratatouille riz | 0 | 1 | 1 | 1 | 1 | 1 |
| risotto aux champignons | 1 | 0 | 0 | 1 | 0 | 1 |
| salade nicoise | 1 | 1 | 1 | 0 | 1 | 0 |
| saumon riz | 1 | 0 | 1 | 0 | 1 | 1 |
| tagliatelles carbonara | 1 | 1 | 0 | 0 | 0 | 1 |
| tagliatelles forestières | 1 | 1 | 0 | 0 | 1 | 0 |
| wok de crevettes | 1 | 0 | 0 | 1 | 1 | 1 |
Nous allons maintenant traduire cette modélisation en code avec CVXPY.
La première étape consiste à définir la variable de décision qui représentera la matrice de répartition des plats.
La classe cp.Variable de CVXPY permet de créer une variable de forme donnée, ici de même dimension que notre matrice de répartition.
Attention, cp.Variable fonctionne avec des objets de type numpy, mais n’est pas compatible directement avec les DataFrames pandas.
Il est donc recommandé d’utiliser pandas pour manipuler et transformer les données en amont, puis de passer à numpy (via .to_numpy()) pour interfacer avec CVXPY.
Dans notre cas, nous précisons que la variable doit être booléenne, c’est-à-dire ne prendre que les valeurs 0 ou 1.
import cvxpy as cp
repartition = cp.Variable(repartition_template.shape, boolean=True)L’étape suivante consiste à définir les contraintes fondamentales du problème.
- Contrainte 1 : Un nombre fixe de plats par période.
Nous souhaitons avoir exactement 2 plats par demi-semaine.
Mathématiquement, cela signifie que la somme des valeurs de chaque colonne de notre matrice
repartitiondoit être égale à 2. - Contrainte 2 : Un plat ne peut être utilisé qu’une fois. Pour éviter de proposer le même plat plusieurs fois, la somme des valeurs de chaque ligne doit être inférieure ou égale à 1. Une valeur de 0 signifie que le plat n’a pas été sélectionné, ce qui est attendu puisque nous avons plus de plats que de places.
CVXPY permet d’exprimer ces contraintes de manière vectorielle, ce qui rend le code à la fois concis et lisible.
meal_appear_once = repartition.sum(axis=1) <= 1
two_meals_per_period = repartition.sum(axis=0) == 2
base_constraints = [
two_meals_per_period,
meal_appear_once,
]Une fois les variables et les contraintes définies, nous pouvons construire l’objet Problem. Cet objet prend deux arguments principaux :
- L’objectif : la fonction à minimiser ou maximiser.
Pour l’instant, nous cherchons simplement à trouver une solution qui respecte les contraintes.
On peut alors se contenter d’un objectif constant :
cp.Minimize(0). Le solveur s’arrêtera dès qu’il trouvera une configuration valide. - Les contraintes : une liste de toutes les règles que la solution doit respecter, c’est à dire la liste
base_constraintsdéfinie plus haut.
L’appel à prob.solve() lance la résolution.
On peut ensuite vérifier le statut du problème et s’assurer de la réussite de l’optimisation.
prob = cp.Problem(cp.Minimize(0), constraints=base_constraints)
prob.solve()
print("Status: ", prob.status) # Status: optimalLa propriété .value de la variable repartition contient la matrice de répartition trouvée par le solveur.
Comme l’objectif est constant, n’importe quelle solution respectant les contraintes est jugée “optimale”.
Le solveur s’arrête donc à la première configuration valide qu’il trouve, et le résultat peut varier d’une exécution à l’autre.
Le code suivant affiche cette matrice, avec les noms correspondant aux lignes et aux colonnes pour une meilleure lisibilité.
On peut y vérifier que nos règles sont bien appliquées : chaque colonne a une somme de 2, et chaque ligne une somme de 1 ou 0.
pd.DataFrame(
repartition.value,
index=repartition_template.index,
columns=repartition_template.columns,
)| week | week0 | week1 | week2 | |||
|---|---|---|---|---|---|---|
| week_part | start | end | start | end | start | end |
| boulette de boeuf - purée | 0 | 0 | 0 | 0 | 1 | 0 |
| colin carottes | 0 | 0 | 0 | 0 | 0 | 1 |
| cordon bleu - petits pois | 1 | 0 | 0 | 0 | 0 | 0 |
| escalope de veau patate grenaille | 0 | 0 | 0 | 1 | 0 | 0 |
| lasagnes bolognaise | 1 | 0 | 0 | 0 | 0 | 0 |
| parmentier de canard | 0 | 0 | 1 | 0 | 0 | 0 |
| ratatouille riz | 0 | 0 | 1 | 0 | 0 | 0 |
| risotto aux champignons | 0 | 0 | 0 | 0 | 0 | 1 |
| salade nicoise | 0 | 1 | 0 | 0 | 0 | 0 |
| saumon riz | 0 | 0 | 0 | 0 | 0 | 0 |
| tagliatelles carbonara | 0 | 0 | 0 | 0 | 1 | 0 |
| tagliatelles forestières | 0 | 0 | 0 | 1 | 0 | 0 |
| wok de crevettes | 0 | 1 | 0 | 0 | 0 | 0 |
Contraintes métier #
Le modèle de base assure une répartition équilibrée, mais il ne garantit pas la diversité au sein d’un même menu. Par exemple, il pourrait proposer deux plats de pâtes simultanément. Nous allons maintenant ajouter une contrainte plus fine pour éviter cela : deux plats partageant un même tag (comme “pâte”, “viande”, ou “poisson”) ne doivent pas être assignés à la même période.
Pour implémenter cette règle, nous devons compter, pour chaque période, le nombre de fois où chaque tag apparaît. La contrainte sera respectée si ce nombre est toujours inférieur ou égal à 1 pour tous les tags.
La première étape consiste à créer une matrice de correspondance entre les plats et les tags.
Cette matrice, que nous nommerons tags_meals, aura les tags en lignes et les plats en colonnes, avec un 1 si un plat est associé à un tag, 0 sinon.
tags_meals = (
pd.DataFrame.from_records(
[{"name": name} | {t: 1 for t in tags} for name, tags in meals]
)
.set_index("name")
.fillna(0)
.astype(int)
.sort_index(axis=0)
.sort_index(axis=1)
.T
)| name | boulette de boeuf - purée | colin carottes | cordon bleu - petits pois | escalope de veau patate grenaille | lasagnes bolognaise | parmentier de canard | ratatouille riz | risotto aux champignons | salade nicoise | saumon riz | tagliatelles carbonara | tagliatelles forestières | wok de crevettes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| boeuf | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| patate | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| pate | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
| poisson | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| porc | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| poulet | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| riz | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| vegetarien | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 |
| viande | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Maintenant, comment obtenir le décompte des tags pour chaque période ? C’est ici qu’intervient une multiplication matricielle.
Le produit de notre matrice tags_meals (dimensions : nombre de tags x nombre de plats) par la matrice de décision repartition (dimensions : nombre de plats x nombre de périodes) donne une nouvelle matrice, tags_periods, dont les dimensions sont nombre de tags x nombre de périodes.
Chaque cellule de cette matrice résultat contient précisément le nombre d’occurrences d’un tag donné pour une période donnée, pour une répartition particulière des plats.
Le calcul est illustré ci-dessous avec notre matrice repartition_template pour visualiser la forme du résultat.
tags_meals @ repartition_template| week | week0 | week1 | week2 | |||
|---|---|---|---|---|---|---|
| week_part | start | end | start | end | start | end |
| boeuf | 2 | 2 | 0 | 1 | 0 | 1 |
| patate | 2 | 1 | 1 | 2 | 0 | 2 |
| pate | 4 | 3 | 0 | 1 | 2 | 2 |
| poisson | 2 | 0 | 1 | 1 | 2 | 3 |
| porc | 1 | 1 | 0 | 0 | 0 | 1 |
| poulet | 0 | 0 | 1 | 1 | 1 | 0 |
| riz | 2 | 1 | 2 | 2 | 2 | 3 |
| vegetarien | 3 | 3 | 2 | 2 | 3 | 2 |
| viande | 4 | 3 | 2 | 3 | 1 | 3 |
Pour illustrer l’interprétation de cette matrice, prenons la valeur 2 en haut à gauche.
Située à l’intersection de la ligne boeuf et de la colonne week0/start, elle signifie que dans cette répartition aléatoire, deux plats contenant du bœuf (boulette de boeuf - purée et lasagnes bolognaise) sont assignés à cette période.
De même, la valeur 3 sur la ligne vegetarien indique la présence de trois plats végétariens (risotto aux champignons, salade nicoise et tagliatelles forestières) sur cette même période.
Pour traduire la contrainte métier, on a alors besoin d’imposer à chaque cellule de valoir au maximum 1.
Cela se traduit mathématiquement par : tags_meals @ repartition <= 1.
L’implémentation dans CVXPY est une traduction directe de cette formule.
no_same_tag_on_same_period = (tags_meals.values @ repartition) <= 1Nous pouvons maintenant relancer la résolution du problème en ajoutant cette nouvelle contrainte à notre liste de règles existantes.
all_constraints = base_constraints + [no_same_tag_on_same_period]
prob_business = cp.Problem(cp.Minimize(0), constraints=all_constraints)
prob_business.solve()
print("Status: ", prob_business.status) # Status: optimal
pd.DataFrame(
repartition.value,
index=repartition_template.index,
columns=repartition_template.columns,
).astype(int)| week | week0 | week1 | week2 | |||
|---|---|---|---|---|---|---|
| week_part | start | end | start | end | start | end |
| boulette de boeuf - purée | 0 | 0 | 0 | 0 | 1 | 0 |
| colin carottes | 1 | 0 | 0 | 0 | 0 | 0 |
| cordon bleu - petits pois | 0 | 1 | 0 | 0 | 0 | 0 |
| escalope de veau patate grenaille | 0 | 0 | 1 | 0 | 0 | 0 |
| lasagnes bolognaise | 0 | 0 | 0 | 0 | 0 | 1 |
| parmentier de canard | 0 | 0 | 0 | 1 | 0 | 0 |
| ratatouille riz | 0 | 0 | 1 | 0 | 0 | 0 |
| risotto aux champignons | 0 | 0 | 0 | 0 | 0 | 0 |
| salade nicoise | 0 | 0 | 0 | 0 | 0 | 1 |
| saumon riz | 0 | 1 | 0 | 0 | 0 | 0 |
| tagliatelles carbonara | 1 | 0 | 0 | 0 | 0 | 0 |
| tagliatelles forestières | 0 | 0 | 0 | 1 | 0 | 0 |
| wok de crevettes | 0 | 0 | 0 | 0 | 1 | 0 |
En analysant les résultats, on observe que la règle est bien respectée. Par exemple, les plats contenant de la viande ne sont jamais associés à d’autres plats de viande. De même, on ne trouve jamais deux plats à base de pâtes ou de pommes de terre dans la même colonne. La diversité au sein de chaque menu est désormais garantie.
Conclusion #
L’optimisation sous contraintes est une approche efficace pour automatiser des tâches de planification complexes. En exprimant la problématique dans un formalisme mathématique de variable, objectif et contraintes, il devient possible de trouver des solutions optimales tout en garantissant le respect des exigences. La maîtrise de ces techniques de modélisation est un atout pour un data scientist, car elle permet de résoudre de manière structurée une large gamme de problèmes opérationnels.