En tant que data engineer, nous ne sommes pas toujours maîtres de nos données sources. En particulier lorsque l’on utilise des données ouvertes, nous sommes à la merci des changements des producteurs de données.
Dans le cadre du projet Euros For Docs, notre source principale de données est la base Transparence Santé. Ce fichier publié chaque jour contient plus de 8 millions de déclarations de rémunérations de professionnels de santé ou d’associations de santé par des laboratoires pharmaceutiques. D’un jour à l’autre, le fichier subit de nombreuses modifications : de nouvelles déclarations sont ajoutées, certaines disparaissent et d’autres sont simplement modifiées.
Des fichiers qui changent quotidiennement #
Dans une optique de suivi des évolutions des déclarations, nous voulons créer un fichier d’historique contenant toutes les versions des déclarations. Grâce à un identifiant unique de chaque déclaration fourni dans le fichier, nous sommes capables chaque jour de comparer une déclaration avec sa dernière valeur historique et d’identifier les changements dans les données sources.
Considérons alors la table suivante comme les dernières valeurs observées des déclarations.
| id | montant | beneficiaire | date | date_modif | date_delete |
|---|---|---|---|---|---|
| 1 | 100 | FEDERATION FRANCAISE DE CARDIOLOGIE | 2025-12-01 | 2025-12-01 | NaT |
| 2 | 200 | FEDERATION DES INFIRMIER | 2025-12-02 | 2025-12-02 | NaT |
| 3 | 300 | ORDRE DES VETERINAIRES | 2025-12-03 | 2025-12-03 | NaT |
| 5 | 500 | APHP | 2025-12-01 | 2025-12-01 | 2025-12-03 |
Considérons maintenant que le fichier du jour contient les déclarations suivantes.
| id | montant | beneficiaire | date_declaration |
|---|---|---|---|
| 1 | 100 | FEDERATION FRANCAISE DE CARDIOLOGIE | 2025-12-01 |
| 2 | 220 | FEDERATION DES INFIRMIERS | 2025-12-02 |
| 4 | 400 | ORDRE DES DIETETICIENS | 2025-12-04 |
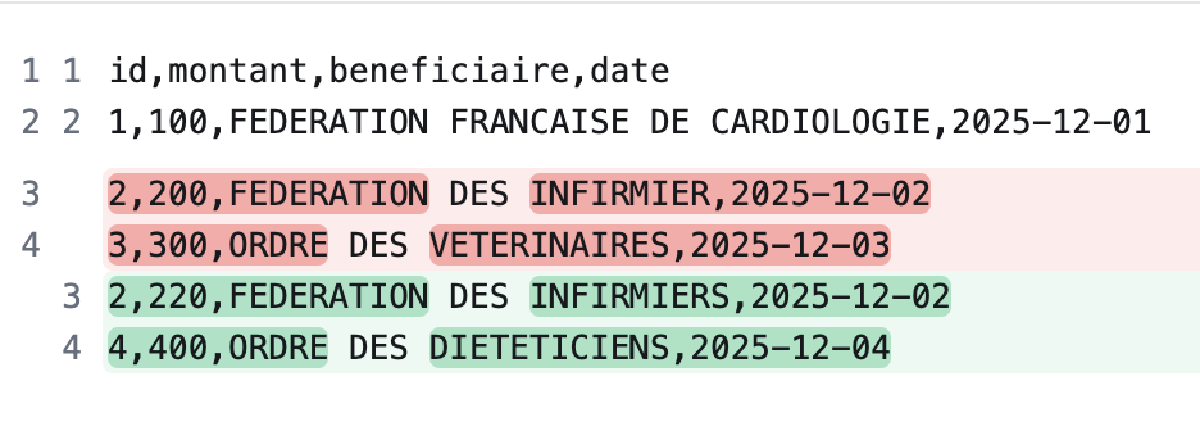
Ce nouveau fichier propose 4 situations différentes.
- La déclaration 1 apparaît dans le fichier du jour avec exactement les mêmes informations que dans le fichier d’historique. Puisque rien n’a changé dans cette déclaration, on ne souhaite rien faire concernant celle-ci dans le fichier d’historique.
- La déclaration 2 existait déjà dans le fichier d’historique mais la version du jour a deux modifications : le montant est passé de 200 à 220 et une typo a été corrigée sur le bénéficiaire (ajout d’un S à la fin). Nous souhaitons garder trace de cette modification et ajouter cette version de la déclaration dans l’historique, avec la date de modification du jour.
- La déclaration 3 n’apparaît plus dans le fichier du jour alors qu’elle existait dans l’historique. Nous voulons alors documenter dans le fichier d’historique la date de disparition de cette déclaration.
- La déclaration 4 est une nouvelle déclaration qui n’était jamais apparue dans le fichier avant cette version. Nous voulons alors l’ajouter dans le fichier d’historique.
- La déclaration 5 n’est pas dans le fichier du jour mais le fichier d’historique mentionne que la déclaration avait déjà disparu dans des versions antérieures du fichier. Nous n’attendons donc aucun traitement sur cette déclaration.
Le cas simple des ajouts et suppressions #
L’apparition de nouvelles déclarations et la disparition d’anciennes sont le cas le plus simple à traiter. Puisque les fichiers nous proposent un id unique pour les déclarations, nous pouvons nous contenter de comparer la liste des ID du fichier d’historique avec celle du fichier du jour. Cette procédure est très simple à mettre en place en SQL et très rapide.
Par exemple, on peut préparer les nouvelles déclarations à injecter dans le fichier avec cette simple requête SQL.
select
declarations.*,
current_date() as date_modif,
cast(null as date) as date_delete
from
declarations
left join historical_declarations hist using (id)
where
hist.id is nullCe qui nous donne la déclaration 4 à injecter.
| id | montant | beneficiaire | date | date_modif | date_delete |
|---|---|---|---|---|---|
| 4 | 400 | ORDRE DES DIETETICIENS | 2025-12-04 | 2025-12-08 | NaT |
Et enfin, on peut identifier la disparition de la déclaration 3 avec la requête suivante.
select
hist.id
from
historical_declarations hist
left join declarations using (id)
where
hist.date_delete is null
and declarations.id is nullUne détection lourde des modifications #
La gestion des déclarations modifiées est bien plus complexe. Le fichier de déclarations contient en réalité une cinquantaine de colonnes que les laboratoires peuvent modifier à volonté. Pour identifier les déclarations modifiées depuis la dernière version du fichier, nous devons créer une condition SQL qui contienne la comparaison des cinquante colonnes une à une pour trouver toutes les déclarations qui étaient déjà présentes dans le fichier de la veille mais dont au moins une valeur a été modifiée. En continuant l’exemple commencé plus tôt, la requête prend la forme suivante.
with
modified as (
select
dec.*
from
declarations dec
join historical_declarations h using (id)
where
h.date_delete is null
and not (
coalesce(h.montant, -1) = coalesce(dec.montant, -1)
and coalesce(h.beneficiaire, '__NULL__') = coalesce(dec.beneficiaire, '__NULL__')
and coalesce(h.date, '1900-01-01') = coalesce(dec.date, '1900-01-01')
)
)
select
*,
current_date() as date_modif,
cast(null as date) as date_delete
from
modifiedCe qui donne la table suivante à injecter dans notre fichier d’historique.
| id | montant | beneficiaire | date | date_modif | date_delete |
|---|---|---|---|---|---|
| 2 | 220 | FEDERATION DES INFIRMIERS | 2025-12-02 | 2025-12-08 | NaT |
Cette stratégie pose deux limitations.
-
La requête elle-même peut rapidement devenir illisible avec 50 conditions (au lieu de 3) à prendre en compte. En vérité, les outils modernes permettent de contourner cette limitation avec le templating. Chez EurosForDocs, c’est du code Python qui organise les appels successifs en SQL. Nous pouvons alors créer dynamiquement la requête grâce à une simple boucle for sur les variables de la déclaration.
-
La deuxième problématique de notre stratégie est la performance. Pour vérifier que deux versions d’une déclaration sont identiques, il faut calculer 50 conditions. Parmi ces conditions, certaines peuvent être particulièrement intenses, telles que la comparaison entre deux longues chaînes de caractères. Ces limitations à l’échelle de plusieurs millions de lignes et de 50 colonnes peuvent rapidement devenir la source principale de lenteur d’un pipeline de données.
Fonctions de hash #
Une autre solution plus performante se base sur la notion de fonction de hash. Une fonction de hash transforme un texte arbitraire en une signature (numérique ou alphanumérique). Cette signature est caractéristique du texte initial dans le sens où appliquer plusieurs fois la fonction de hash sur le même texte donnera toujours la même signature. Par contre deux textes qui diffèrent, même par une seule typographie, obtiendront des signatures radicalement différentes.
Prenons un cas simple : les numéros de sécurité sociale français. La plupart des numéros sont une combinaison de nombres liés à notre date et lieu de naissance. Les deux derniers chiffres sont par contre beaucoup moins connus : ils sont justement utilisés dans le cadre d’une fonction de hash basique.
L’algorithme de Luhn est une manière de combiner les chiffres d’un numéro pour obtenir un entier comme signature. L’image ci-dessous montre comment calculer cette signature pour une combinaison de chiffres arbitraire.
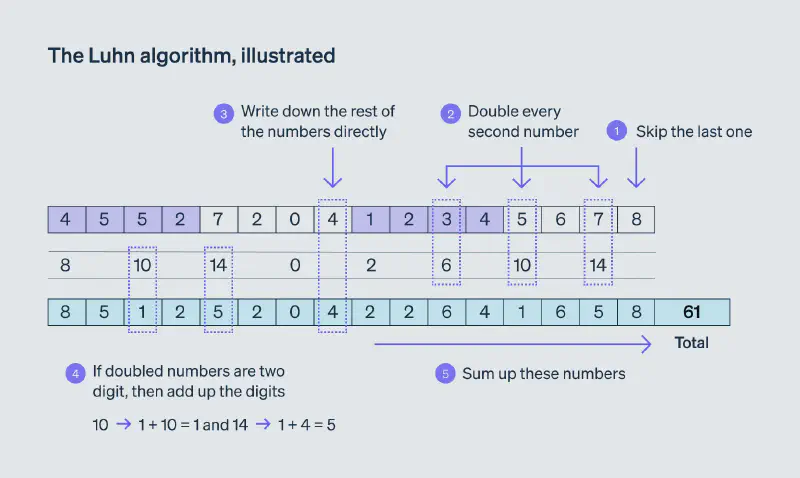
En général, l’algorithme de Luhn ne se limite pas à calculer cette signature. Dans le cas du numéro de sécurité sociale, les deux derniers numéros sont ajoutés et choisis spécifiquement pour forcer la signature à être un multiple de 10. Ainsi, si nous rencontrons un numéro avec une signature qui n’est pas un multiple de 10, nous pouvons être sûrs que ce numéro contient au moins une erreur. Il est possible d’utiliser cette propriété pour vérifier que le chiffre fourni dans un formulaire n’est pas invalide sans avoir à demander à l’assurance maladie la liste de tous les numéros valides.
Limitations des hash #
Une des limitations évidentes des fonctions de hash est qu’il existe bien moins de signatures uniques que de textes possibles. Dans le cas des numéros de sécurité sociale, seules 10 signatures sont possibles, dont une seule (le 0) a vraiment un sens. La plupart des systèmes informatiques encodent aujourd’hui les entiers sur 64 bits : ce qui représente 2**64=18 446 744 073 709 551 616 signatures uniques. Même si ce chiffre est énorme, il est insignifiant par rapport à l’ensemble de tous les textes (et leurs sous-parties) qui peuvent exister. De nombreux textes vont donc partager la même signature.
Le résultat d’une fonction de hash peut sembler aléatoire et deux textes très similaires peuvent obtenir des nombres radicalement différents. Cela entraîne que la probabilité que deux textes différents partagent la même signature est d’autant plus faible que le nombre de signatures disponibles est grand. Ainsi, on peut toujours choisir une fonction de hash avec suffisamment de signatures disponibles pour considérer nulle la probabilité que deux textes différents de notre jeu de données partagent la même signature.
Détection des modifications grâce au hash #
EurosForDocs utilise alors une fonction de hash pour identifier les déclarations modifiées entre deux versions de notre fichier source. Pour chaque déclaration passée ou présente, les 50 colonnes du fichier sont concaténées pour créer un gros texte. On peut ensuite faire passer ce texte dans une fonction de hash pour obtenir une signature de cette version de la déclaration. L’identification des modifications est alors très rapide et très simple à implémenter : on regarde pour chaque déclaration si la valeur actuelle de la signature correspond à celle de la veille.
| id | montant | beneficiaire | date | date_modif | date_delete | declaration_hash | pre_hash_content |
|---|---|---|---|---|---|---|---|
| 1 | 100 | FEDERATION FRANCAISE DE CARDIOLOGIE | 2025-12-01 | 2025-12-01 | NaT | 5282952966449529016 | FEDERATION FRANCAISE DE CARDIOLOGIE1002025-12-01 |
| 2 | 200 | FEDERATION DES INFIRMIER | 2025-12-02 | 2025-12-02 | NaT | 2026300923310215632 | FEDERATION DES INFIRMIER2002025-12-02 |
| 3 | 300 | ORDRE DES VETERINAIRES | 2025-12-03 | 2025-12-03 | NaT | 13336717800038872971 | ORDRE DES VETERINAIRES3002025-12-03 |
| 5 | 500 | APHP | 2025-12-01 | 2025-12-01 | 2025-12-03 | 17315167167027391093 | APHP5002025-12-01 |
Nous pouvons ensuite directement calculer ce hash sur les nouvelles déclarations et comparer avec le hash historique pour identifier les déclarations modifiées.
WITH declas_with_hash AS (
SELECT
*,
HASH(
CONCAT(
COALESCE(beneficiaire, '__NULL__'),
COALESCE(montant::VARCHAR, '__NULL__'),
COALESCE(date::VARCHAR, '__NULL__')
)
) AS declaration_hash
FROM declarations
)
SELECT
old.id,
old.declaration_hash::VARCHAR AS declaration_hash,
declas_with_hash.declaration_hash::VARCHAR AS updated_declaration_hash
FROM historical_declarations
INNER JOIN declas_with_hash ON historical_declarations.id = declas_with_hash.id| id | declaration_hash | updated_declaration_hash |
|---|---|---|
| 1 | 5282952966449529016 | 5282952966449529016 |
| 2 | 2026300923310215632 | 1955208196671589357 |
Cette méthode permet d’obtenir des gains de performances. Chaque jour, nous devons uniquement comparer deux entiers pour chaque déclaration au lieu d’une cinquantaine de colonnes : ce qui consomme beaucoup moins de mémoire (pas besoin de lire les chaînes de caractères) et est beaucoup plus rapide.
Conclusion #
Les fonctions de hash offrent une alternative efficace pour détecter les modifications dans des jeux de données volumineux et fréquemment mis à jour. En transformant des ensembles de colonnes complexes en signatures numériques simples, elles permettent de simplifier significativement les requêtes SQL et d’améliorer les performances des pipelines de données.
Dans le cas d’EurosForDocs, cette approche a permis de réduire la complexité de la détection des modifications de plusieurs dizaines de conditions SQL à une simple comparaison d’entiers. Les gains en termes de temps d’exécution et de consommation mémoire sont particulièrement notables lorsque l’on traite des millions de lignes quotidiennement et que l’on doit se contenter de machines avec peu de mémoire.
Cette technique s’applique à de nombreux autres cas d’usage en data engineering : suivi de versions de fichiers, détection de doublons, validation d’intégrité de données, ou encore déduplication. Il est important de choisir une fonction de hash adaptée à la taille de votre jeu de données pour minimiser les risques de collisions, même si ceux-ci restent négligeables dans la plupart des contextes pratiques.