
Présentation effectuée dans le cadre du meetup Bordeaux ApérOps le 11 février 2026.
L’enjeu de la transparence dans la santé #
Le scandale du Mediator #
Le Mediator est un médicament dérivé de l’amphétamine, commercialisé par le laboratoire Servier comme antidiabétique à partir de 1976. Au-delà de son cadre officiel d’utilisation, il a toutefois été massivement prescrit comme coupe-faim pendant plus de trente ans. Durant toutes ces années, il aurait entraîné la mort de plus de 1500 personnes et créé de graves pathologies à des milliers d’autres.
Le scandale a éclaté en 2009, lorsque la pneumologue Irène Frachon publie le livre Mediator 150 mg : combien de morts ?.

Transparence Santé #
Suite à ce scandale qui avait mis en lumière des conflits d’intérêts dans les organismes de contrôle, une loi a été votée pour imposer aux laboratoires la déclaration toute rémunération ou avantage en nature versé à des professionnels de santé ou tout autre acteur lié à la santé (associations, entreprises). Toutes ces déclarations ont été mises à disposition du public à travers une plateforme d’open data Transparence Santé.
![]()
Une transparence floue #
Bien que l’on puisse considérer la transparence comme acquise grâce à la disponibilité des données, l’objectif n’est cependant pas atteint. La faible qualité des données, principalement le manque de normalisation et les doublons, rendent l’exploitation des données très compliquée pour toute personne sans compétences data.
Une simple recherche d’un médecin traitant peut rapidement tourner au casse-tête. L’exemple ci-dessous montre que plusieurs bénéficiaires apparaissent plusieurs fois chacun. Le maximum que nous voyons ici est 3 doublons mais il est possible d’en avoir plusieurs dizaines pour des hôpitaux ou autres associations au nom complexe.
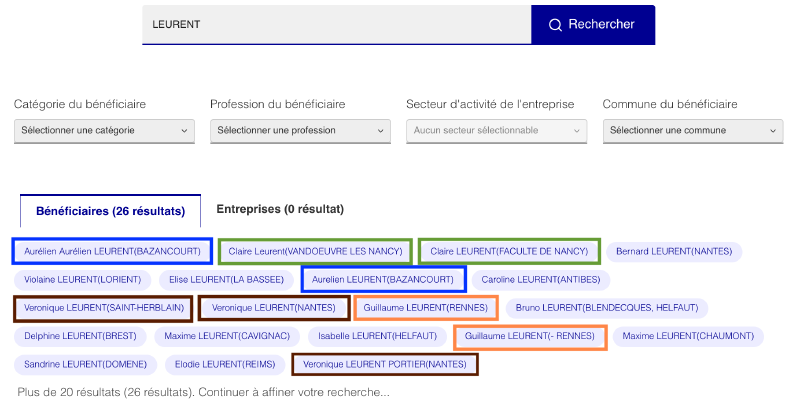
Les difficultés d’exploitation persistent lorsque l’on s’intéresse à un compte bénéficiaire particulier. L’interface ne nous permet de voir qu’une liste de déclarations sans aucun moyen d’agréger les montants par exemple. Lorsque le compte bénéficie de nombreuses déclarations, il devient ingérable pour une personne sans connaissances en gestion de données d’avoir une vision globale et fiable des risques de conflit d’intérêts.
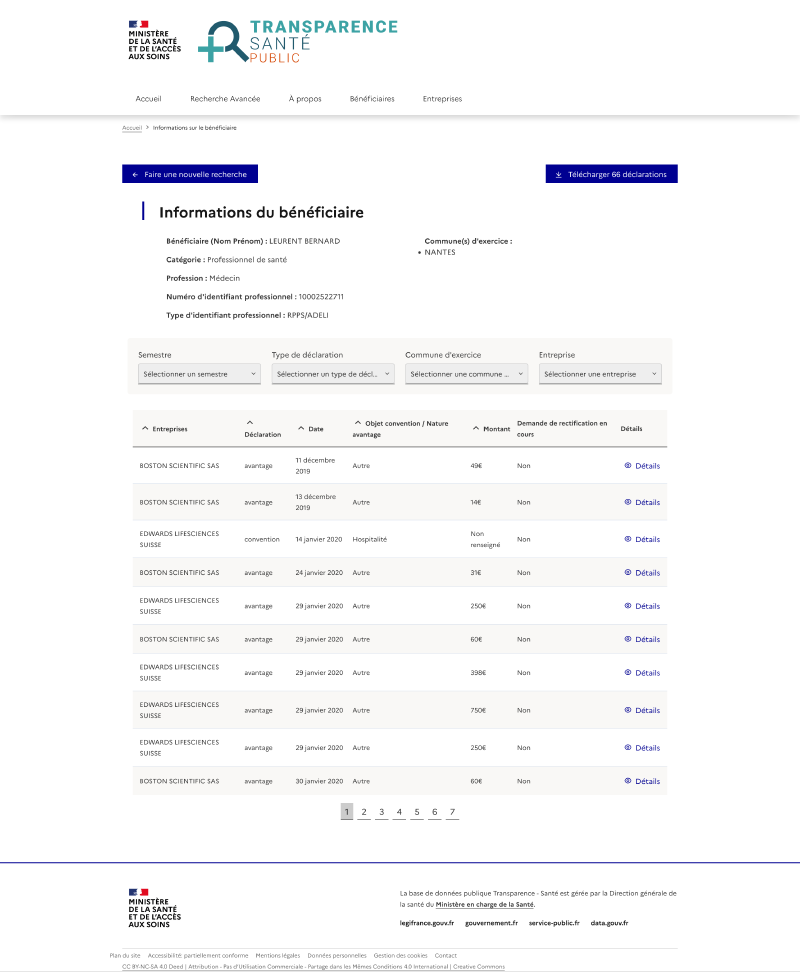
La qualité des données comme base de la transparence #
L’association EurosForDocs #
EurosForDocs a alors été créée pour résoudre ces problématiques et transformer la base Transparence Santé en un vrai outil de lutte contre les conflits d’intérêts. L’association s’organise autour de 3 objectifs principaux :
- le nettoyage des données, en particulier la fusion des doublons;
- la mise à disposition des données dans un tableau de bord interactif et intuitif;
- l’accompagnement de journalistes, chercheurs et citoyens pour l’exploitation des données.
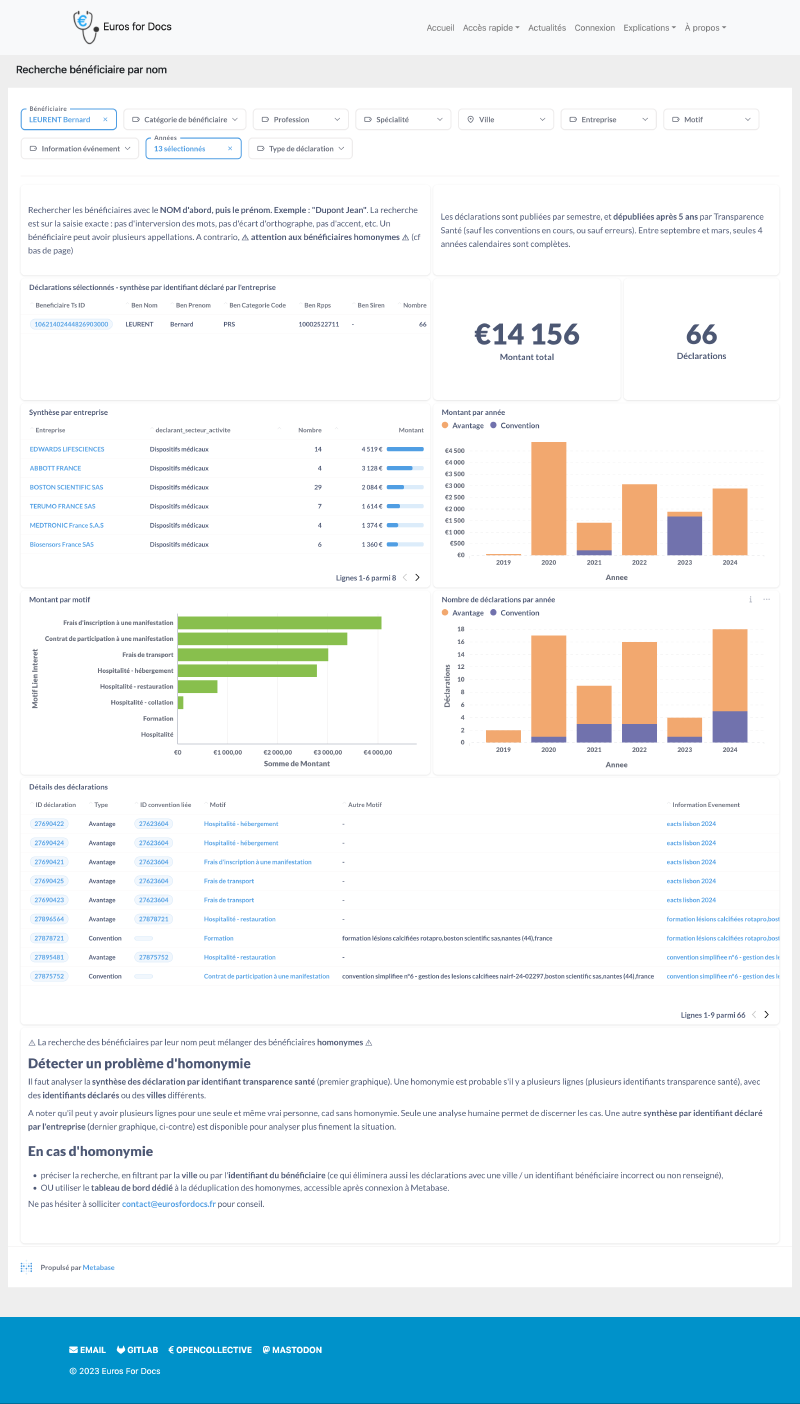
La route vers l’unification des bénéficiaires #
Le besoin d’identifiants fiables #
Lorsque l’on manipule des données pour lesquelles une même entité peut apparaître à plusieurs reprises, il est toujours préférable d’attribuer un numéro d’identification à chacune des identités. Ainsi, il est aisé de sélectionner que les données relatives à une entité spécifique en utilisant cet identifiant. Sur Transparence Santé, il serait pratique d’avoir un identifiant unique pour un bénéficiaire, quelles que soient les erreurs de déclaration que pourraient faire l’entreprise.
Justement l’administration a depuis longtemps trouvé une solution à ce problème. Les professionnels de santé ayant le droit d’exercer en France doivent s’enregistrer et se voient attribuer un identifiant national : le RPPS. De même, toute entreprise ou association doit s’enregistrer et reçoit respectivement un numéro SIREN ou un numéro RNA (voire les deux).
En théorie les laboratoires ont toutes les informations pour créer un jeu de données propre et bien structuré. Malheureusement, les entreprises déclarantes ne les utilisent pas systématiquement. Au contraire, près de 50% des déclarations concernant des personnes morales ne déclarent pas de numéro SIREN ou RNA. Cela signifie que près de 500 millions d’euros d’influence ne peuvent pas être facilement rattachés à une institution.

L’enjeu principal d’EurosForDocs est alors de tenter de réattribuer un de ces identifiants nationaux à chacun des bénéficiaires de la base de données.
Indexation des bénéficiaires #
Lorsque les entreprises ne déclarent pas d’identifiant national, aucun autre identifiant (même interne) n’est créé. Ainsi une entreprise peut déclarer une rémunération supplémentaire envers une entité mais en la nommant différemment. Le phénomène est amplifié si cette entité reçoit également des rémunérations d’autres entreprises. Au final, on peut avoir plusieurs mentions, potentiellement très différentes, de la même entité sans lien explicite entre elles.
Notre stratégie de déduplication des bénéficiaires s’organise alors en deux étapes. Tout d’abord on crée un identifiant unique à chaque variante déclarée des bénéficiaires. A travers une exploration des données, nous avons décidé qu’une entreprise qui déclare deux fois les mêmes (nom, prénom, profession, code_postal) fait référence à une même entité. Nous utilisons alors une fonction de hashage qui transforme cette combinaison de caractéristiques en un entier aléatoire spécifique à cette combinaison. Cet entier va nous servir à identifier de manière unique un compte bénéficiaire. Cet article présente plus en détail les fonctions de hashage dans un autre cas d’usage.
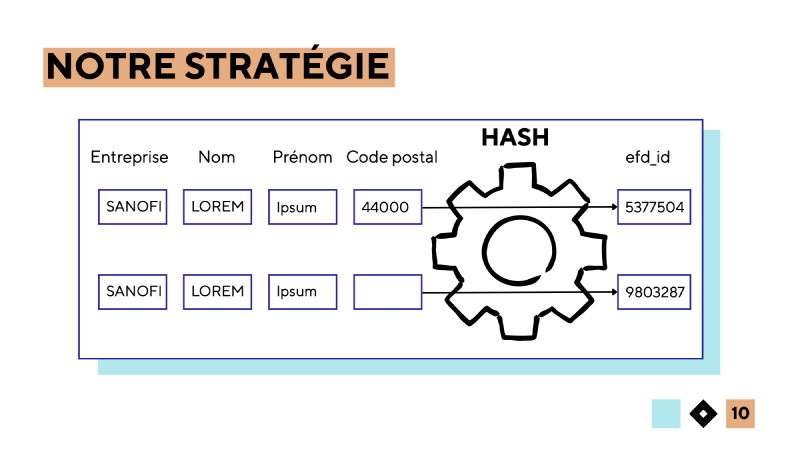
Une fois que nous avons défini nos comptes bénéficiaire, nous chercherons à les nettoyer puis à identifier tous les comptes qui font référence à la même entité pour, à terme, les fusionner.
Nettoyage des RPPS incohérents #
Lorsque nous avons défini les informations qui définissaient un compte bénéficiaire, nous avions observé que pour une même combinaison de (nom, prénom, profession, code_postal), certaines entreprises pouvaient ajouter différents modes d’identification. Par exemple, une déclaration contiendrait le numéro RNA et une autre le numéro SIREN. Nous avons donc décidé de garder cette diversité au sein d’un compte bénéficiaire.
Il arrive cependant régulièrement que pour des professionnels de santé, deux numéros RPPS distincts sont présents dans un même compte bénéficiaire. Après analyse détaillée de ces cas, nous en avons observé qu’un seul RPPS est cohérent avec les autres informations déclarées et que les autres numéros correspondent à des professionnels très différents.
Notre enjeu étant de fusionner les bénéficiaires autour d’un numéro RPPS, nous devons nous assurer que chaque compte bénéficiaire est cohérent en soi. Grâce à l’annuaire des professionnels de santé, nous pouvons obtenir les informations officielles reliées à un numéro RPPS. Un système de scoring (fuzzy matching) entre les informations déclarées et les informations officielles de chaque RPPS nous permet d’estimer la cohérence entre les informations officielles et déclarées, et ne conserver que le numéro RPPS le plus pertinent.
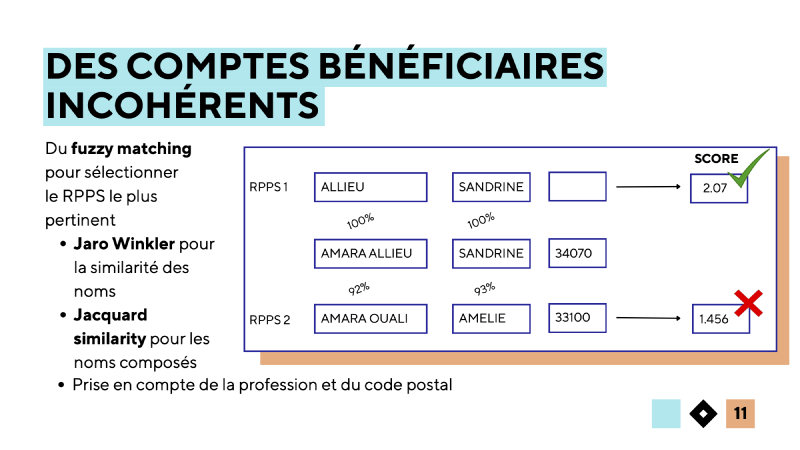
Attribution du RPPS #
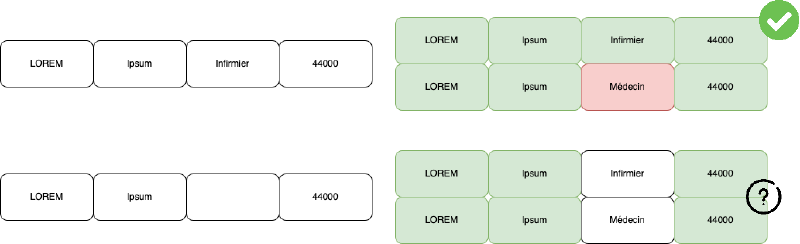
De nombreuses déclarations n’ont pas le luxe d’avoir même un seul numéro RPPS. Nous cherchons alors à relier les informations documentées par l’entreprise avec un.e professionnel.le de santé de l’annuaire. Nous cherchons d’abord à trouver une correspondance exacte sur le nom, prénom, profession et code postal. Nous ajoutons à cette logique des mécanismes pour traiter le cas de noms composés pour lesquels seule une partie peut être renseignée, ou l’ordre inversé.
De nombreuses déclarations ont des informations manquantes ou erronnées, ce qui rend la première étape inefficace pour retrouver un RPPS. Nous testons alors les comptes bénéficiaires non identifiés avec des contraintes plus souples, par exemple ne pas considérer le code postal. Avec un relâchement des contraintes, le risque de tomber sur des homonymes augmente. Nous n’attribuons alors un RPPS que s’il n’y a qu’un seul professionnel de santé correspondant aux contraintes.
Attribuer des liens directs #
Une fois que nous avons attribué un maximum d’identifiants RPPS aux bénéficiaires, nous allons chercher à identifier directement des liens entre des comptes. On espère ainsi que les comptes sans RPPS puissent en obtenir un de manière indirecte. De même on espère que les comptes de personnes morales, pour lesquels nous n’avons pas de mécanisme pour retrouver le SIREN, puissent en obtenir un.
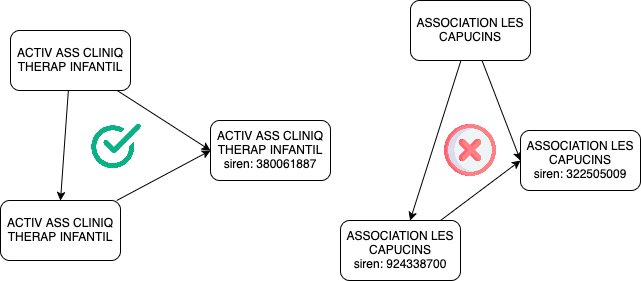
De manière similaire à la création des comptes de bénéficiaires, nous regroupons les comptes par (nom, prénom, code postal et profession).
Si le groupe regroupe plusieurs numéros SIREN (ou RNA ou RPPS) distincts, nous considérons que ces informations font référence à plusieurs entités distinctes (potentiellement à cause d’erreurs de déclarations) et ne faisons rien.
Dans le cas contraire, nous créons un lien entre tous ces comptes pour les considérer comme appartenant à la même entité.
Relier les association par machine learning #
Contrairement aux professionnels de santé pour lesquels il y a relativement peu de variations possibles (à part le sujet de noms composés), les associations (ou personnes morales en général) peuvent être nommées de manière très différente tout en maintenant la clarté de l’entité ciblée. Ce cas d’étude Euros For Docs explore un cas particulier.
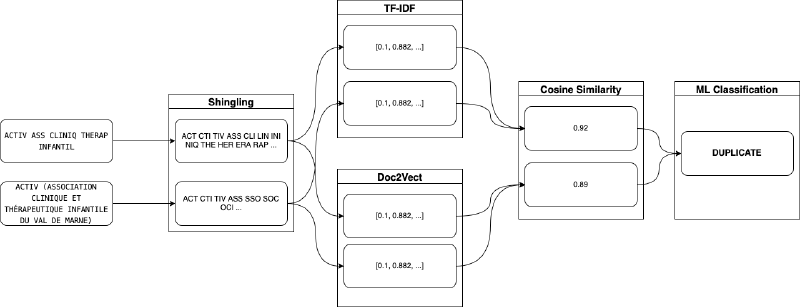
Nous cherchons donc à identifier si deux noms potentiellement très différents (du point de vue des similarités standard entre chaînes de caractères) font référence à la même entité. Pour obtenir des éléments à comparer entre les deux noms, nous appliquons une méthode appelée shingles. L’idée est de découper notre nom d’association en toutes les combinaisons de 3 lettres consécutives. Le nom d’association est alors transformé en une phrase dont les éléments ne sont pas des mots mais nos trigrammes. À partir de cette nouvelle représentation de chaque nom, nous pouvons appliquer des techniques de langage naturel (NLP) standard pour évaluer la similarité entre les deux noms. Enfin, un modèle de machine learning va utiliser les différentes notions de similarité et déterminer la meilleure manière de les combiner pour identifier les paires de noms d’une même entité.
Fusion des comptes #
À ce niveau du traitement des données, les comptes bénéficiaires peuvent être reliés à un ou plusieurs identifiants nationaux mais également à un ou plusieurs autres comptes. Pour recréer une entité bénéficiaire, nous représentons l’ensemble des comptes et des relations sous forme de graphe. Cette représentation nous permet d’utiliser un algorithme pour regrouper tous les comptes bénéficiaires reliés les uns aux autres même de manière indirecte. Chacun de ces blobs est alors interprété comme une entité. Les comptes appartenant à l’entité seront fusionnés et les informations agrégées de l’entité serviront à normaliser les informations bénéficiaires dans les déclarations. Pour plus de détails sur la fusion des comptes, voir cet article dédié
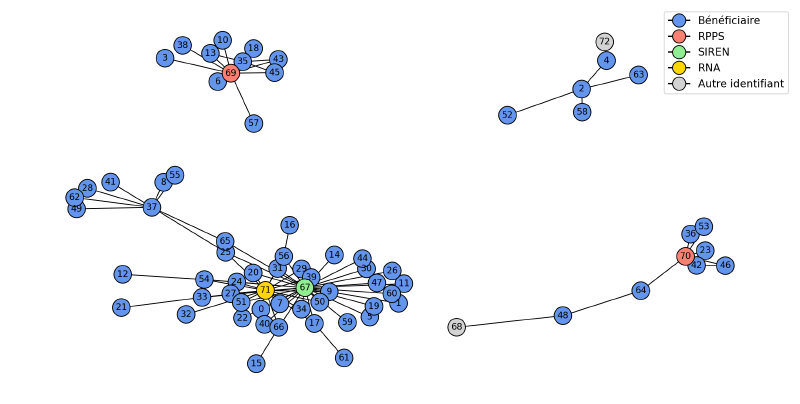
Toujours pour des raisons de qualité de données, il peut arriver que plusieurs SIREN (ou RPPS, RNA) soient présents dans un même blob. Un identifiant national devant identifier de manière unique une entité, cette situation nous informe qu’un ou plusieurs liens dans notre base sont faux et regroupent deux comptes correspondant à des entités séparées. Nous sommes capables de facilement identifier ces situations (à défaut de pouvoir les corriger) et nous empêchons la fusion des comptes appartenant à ces blobs. C’est pour cette raison qu’en pratique, les comptes bénéficiaires des CHU sont rarement fusionnés car il y a toujours une déclaration pour introduire un mauvais SIREN ou le RNA d’une association.
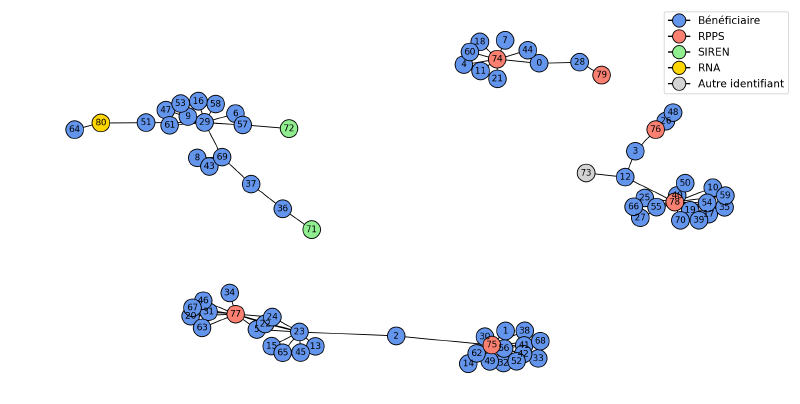
Sans qualité des données, la transparence est un mythe #
Ce travail de nettoyage d’EurosForDocs améliore sensiblement la qualité des données Transparence Santé. La capacité à identifier de manière unique et précise un professionnel de santé (et bientôt une association) facilite énormément le travail des journalistes et citoyens, en témoignent les nombreuses collaborations dans l’écriture d’articles.

