
Cet article est issu d’une présentation donnée à la Holberton School à Bordeaux, puis remaniée pour une lecture continue. Les slides associées sont disponibles ici.
L’association Data for Good #
Data for Good est née d’un constat simple : la tech et ceux qui la maîtrisent servent trop souvent à optimiser des clics publicitaires. L’association a été créée pour mettre ces compétences au service du bien commun. Elle fait le lien entre des associations à forte expertise métier mais peu équipées techniquement, et des bénévoles du secteur tech qui veulent s’engager pour des causes en phase avec leurs valeurs.
En dix ans, Data for Good a encadré plus de 130 projets et mobilisé plus de 8 000 bénévoles. Certains ont eu un fort écho médiatique, comme Carbon Bomb, qui documente les forages pétroliers susceptibles de faire bondir les émissions de CO₂. L’association reste très active : en 2025, plus de 15 projets ont rassemblé plus de 1 000 bénévoles sur des sujets variés. Parmi les plus récents, une cartographie nationale de la qualité de l’eau du robinet, Dans Mon Eau, réalisée à partir des données publiques de relevés et d’analyses.

Data for Good n’est pas uniquement à Paris : elle se déploie progressivement dans toute la France, avec des antennes dans plusieurs villes. À Bordeaux par exemple, l’antenne organise environ un événement par mois et réunit en moyenne une vingtaine de personnes.
Le format principal d’action de Data for Good est la saison : un hackathon de trois mois pendant lequel une douzaine d’associations présélectionnées proposent des projets à des bénévoles. Ceux-ci choisissent un sujet selon leurs valeurs, leur appétence ou le défi technique qu’ils veulent relever, et co-construisent la solution avec l’association. La saison court en général de janvier à mai. Même en dehors de cette période de hackathon, il est possible de contribuer à Data for Good.
Contrairement à un hackathon classique, les solutions ne restent pas dans un tiroir après la démo : elles sont utilisées par les associations, qui ont souvent des besoins de suivi. Les bénévoles prolongent régulièrement leur investissement auprès de l’association et en deviennent souvent membres à part entière. Les projets continuent ainsi leur activité pendant potentiellement plusieurs années même s’ils sont moins médiatisés. Pyronear en est un bon exemple : outil de détection des départs de feu en forêt à partir des images de caméras de surveillance, créé et accéléré par Data for Good, il est aujourd’hui utilisé par les pompiers. Une équipe de bénévoles continue de faire évoluer l’outil. Un des chantiers actuels consiste à améliorer la localisation des départs de feu afin de guider les pompiers vers le bon versant en vallée encaissée, ce qui permet de gagner un temps précieux. Euros for Docs fait également partie de ces projets hors saison.
Pour un projet valorisant, que ce soit dans le cadre d’un CV ou d’une fin de formation, il est possible de s’inscrire sur le site de Data for Good et de rejoindre le réseau. La plateforme recense les projets toujours en activité qui recherchent des bénévoles ; les référents peuvent être contactés afin de construire une collaboration qui réponde à la fois aux besoins de l’association et aux objectifs pédagogiques.

Euros For Docs #
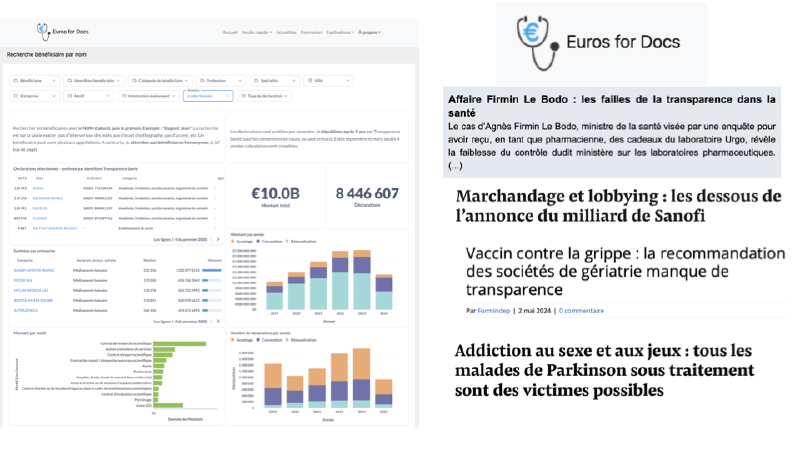
À la fin des années 2000, un scandale sanitaire majeur a éclaté en France. Le Mediator, médicament vendu par les laboratoires Servier, a causé plus de 1 500 décès en trente ans et provoqué des atteintes cardiaques et pulmonaires graves chez plusieurs dizaines de milliers de personnes. Les contrôles ont révélé que les mécanismes de vérification des médicaments avaient failli, en raison de conflits d’intérêts entre Servier et les instances de contrôle. Pour y remédier, le Parlement a voté en 2011 la loi « Transparence Santé », qui oblige les laboratoires à déclarer sur une plateforme publique tout versement ou avantage accordé à un professionnel ou une association de santé. Ces données sont publiées sur data.gouv.fr pour permettre à chacun d’évaluer les conflits d’intérêts dans le secteur. La base Transparence Santé ne remplit toutefois pas pleinement ses objectifs.
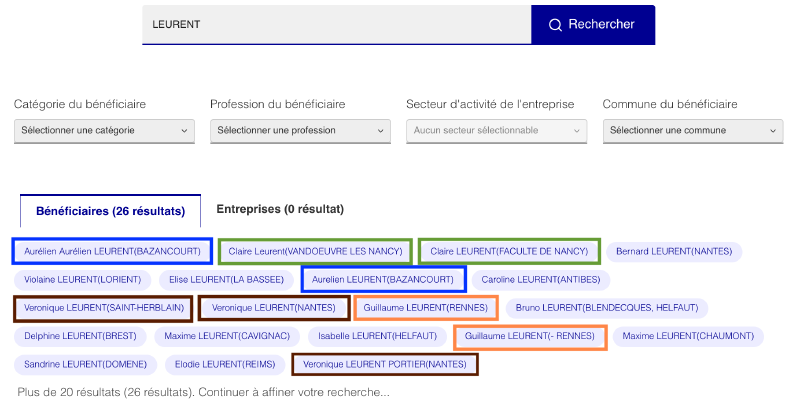
Premier problème : une recherche sur un professionnel ou une association renvoie souvent plusieurs fiches distinctes pour une même personne ou structure. Pour avoir une vision fiable des conflits d’intérêts d’un bénéficiaire, il faut donc regrouper manuellement toutes ces variantes.
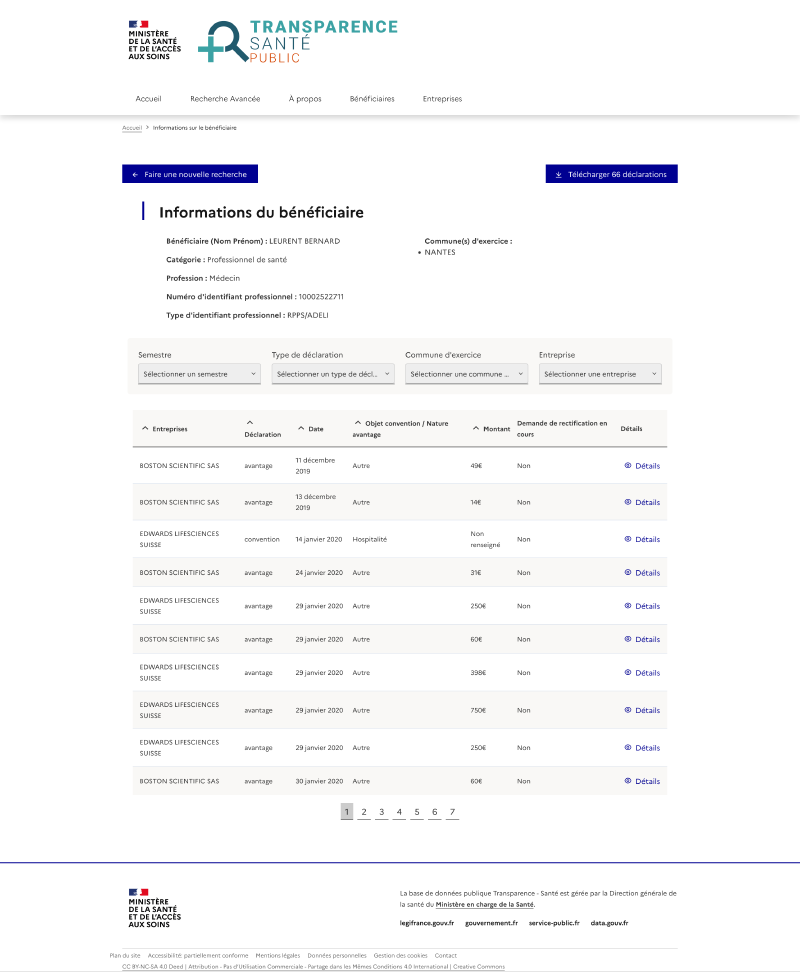
Deuxième problème : en ouvrant une fiche, on obtient surtout une liste de déclarations brutes ; pour des indicateurs agrégés (montant total, répartition par laboratoire), il faut télécharger un fichier Excel et faire soi-même l’analyse, ce qui reste peu accessible pour beaucoup de citoyens et de journalistes.
Euros for Docs a été créée pour pallier ces deux limites et rendre la transparence sanitaire réellement exploitable. L’association poursuit deux objectifs : améliorer la qualité des données en fusionnant les variantes d’un même professionnel, et proposer sur son site un tableau de bord donnant un accès direct aux principaux indicateurs de conflits d’intérêts. Aujourd’hui, les journalistes citent en priorité Euros for Docs plutôt que Transparence Santé comme source pour ces données.
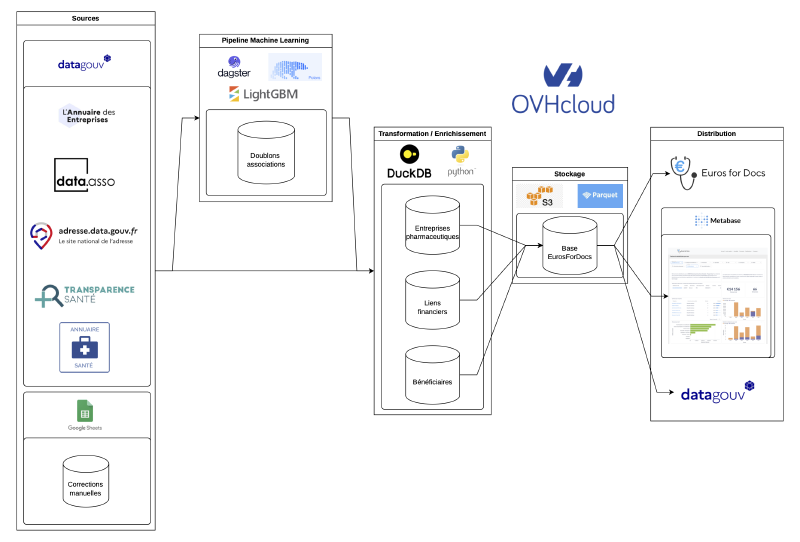
L’infrastructure Euros For Docs #
L’architecture générale du projet est représentée dans l’image suivante. Chaque jour, un job récupère sur data.gouv.fr la base Transparence Santé ainsi que d’autres sources : annuaire des professionnels de santé, annuaire des associations, et des Web API pour enrichir les adresses des déclarations. À partir de ces jeux de données, une pipeline enchaîne des requêtes SQL pour nettoyer et enrichir la base Transparence Santé et produire une base consolidée des liens financiers entre professionnels de santé et laboratoires. Cette base est envoyée vers un stockage cloud pour mise à disposition du public. Le site web la récupère chaque matin et met à jour le tableau de bord d’analyse des conflits d’intérêts proposé aux journalistes.
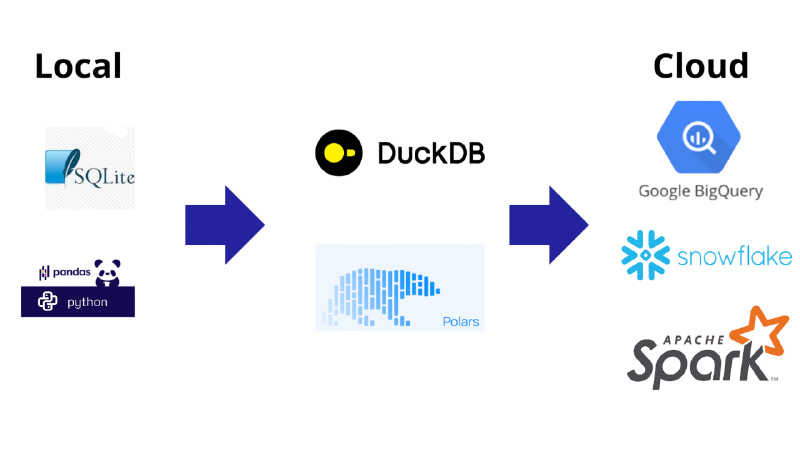
Une particularité de l’infrastructure est l’usage de DuckDB.
Longtemps, la data a oscillé entre deux modèles : le traitement local sur un laptop, tant que la donnée tient entièrement en RAM (sinon pandas.read_csv échoue), et le cloud, qui traite les données par morceaux entre plusieurs serveurs.
Le cloud coûte cher : stockage, calcul, et expertise pour le configurer et le maintenir.
Depuis quelques années émerge un troisième paradigme, souvent qualifié de « medium data » : découper un jeu trop volumineux pour la RAM en morceaux traités successivement, tout en conservant l’ensemble sur une seule machine (un seul disque dur).
Pour la plupart des acteurs, les volumes ne dépassent pas quelques dizaines de téraoctets, des tailles gérables sur du matériel standard.
Avec DuckDB, notre pipeline traite environ 100 Go de données sur des machines OVH peu coûteuses, avec seulement 4 Go de RAM, déjà utilisées par Euros for Docs pour héberger le site.
En pratique, le pipeline ne génère donc pas de coût cloud supplémentaire.
La normalisation des bénéficiaires #
L’un des volets les plus techniques de la pipeline concerne le nettoyage des bénéficiaires. Il s’agit d’identifier toutes les variantes d’un même bénéficiaire, de les fusionner et de les normaliser pour obtenir une base finale cohérente.
Attribution d’un numéro interne #
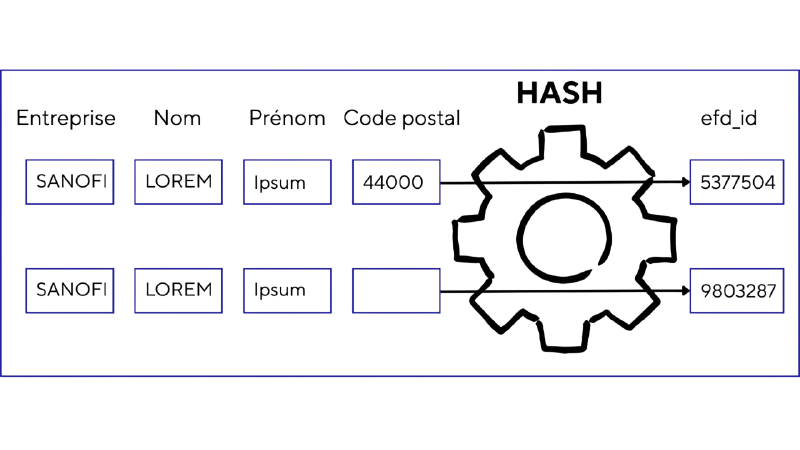
La première étape consiste à attribuer un identifiant unique à chaque entité que l’on considère comme une même entité réelle.
Les identifiants sont au cœur de la pipeline : ils permettent d’identifier les entités et de simplifier le code en référençant un seul nombre plutôt qu’un ensemble de formulations.
Nous avons analysé le jeu Transparence Santé et considérons que la combinaison (entreprise déclarante, nom, prénom, profession, code postal) désigne toujours la même entité (professionnel de santé ou association) dans le monde réel ; nous attribuons donc un numéro unique à chaque combinaison.
Techniquement, nous utilisons une fonction de hachage qui prend en entrée une chaîne formée de ces champs et renvoie un entier en apparence aléatoire. Une même combinaison, reprise dans plusieurs déclarations, produit toujours le même entier. Une chaîne légèrement différente produit un entier différent, sans lien apparent avec les autres. Le risque est la collision : deux chaînes distinctes (par exemple à cause de coquilles) qui produiraient le même hash. En choisissant un espace de hachage bien plus grand que le nombre de combinaisons attendu, on peut considérer la probabilité de collision comme négligeable.
Une même entité réelle peut toutefois apparaître sous plusieurs identifiants internes (par exemple noms composés déclarés différemment). Les étapes suivantes de la pipeline ont pour but de relier les comptes générés par ces variantes entre eux pour à terme les fusionner.
Correction de RPPS faux #
À l’étape précédente, nous avons créé des identifiants internes censés cibler une seule entité. En explorant les données, nous avons constaté qu’un même compte bénéficiaire peut avoir plusieurs numéros RPPS renseignés. Le RPPS est le numéro d’identification national des professionnels de santé en France, nécessaire pour exercer. Cette situation crée un paradoxe : un identifiant interne est censé désigner un seul professionnel, mais pour un même identifiant interne on trouve plusieurs RPPS, qui, eux, désignent des personnes différentes. L’analyse montre que dans ces cas, un seul RPPS correspond vraiment aux informations déclarées (vérification via le répertoire des professionnels de santé), les autres renvoyant à des personnes sans lien (noms, prénoms ou villes différents). Nous avons mis en place une stratégie pour garder le RPPS pertinent et écarter les autres.
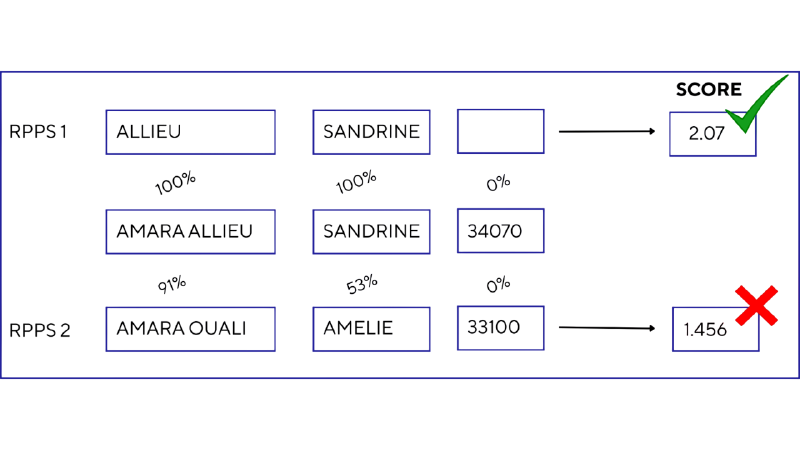
Concrètement, nous comparons d’un côté les informations déclarées par l’entreprise{nom, prénom, code postal, profession) et de l’autre les informations officielles du répertoire des professionnels de santé. L’étape suivante consiste à calculer un score de similarité et à conserver le RPPS qui obtient le meilleur score. Le score combine plusieurs éléments : similarité des chaînes nom/prénom (distance de Jaro-Winkler), prise en compte des noms composés (une seule partie du nom peut être déclarée ici ou là), et des correctifs liés à la profession et au code postal. Dans l’exemple présenté, une déclaration concerne « Sandrine Amara-Allieu » mais deux RPPS sont candidats (Sandrine Allieu et Amélie Amara-Ouali) ; la seule similarité Jaro-Winkler sur le nom favoriserait le mauvais RPPS, un correctif sur les noms composés permet de retenir le bon.
Réattribution des RPPS #
Une fois corrigés les comptes avec plusieurs RPPS, il reste ceux qui n’en ont aucun. Nous utilisons à nouveau le répertoire des professionnels de santé pour retrouver une personne correspondant aux informations de la déclaration. Contrairement à l’étape précédente, le fuzzy matching est exclu : un nom et un prénom proches dans le répertoire produiraient trop de faux positifs. La méthode repose donc sur du matching exact, via une série de règles encadrées.
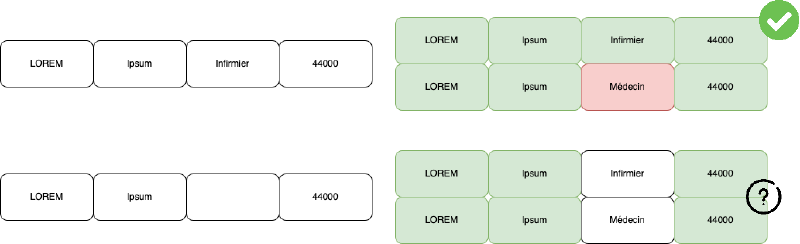
La règle la plus stricte consiste à chercher dans le répertoire une personne avec exactement le même nom, prénom, profession et code postal que la déclaration ; on peut alors lui réattribuer le RPPS. Quand la déclaration ne contient pas la profession ou le code postal, on assouplit les critères (par exemple nom + prénom + code postal uniquement). On peut alors trouver des correspondances, mais aussi des ambiguïtés : deux personnes avec le même nom dans la même ville et des métiers différents. Dans ce cas, on ne sait pas quel RPPS attribuer. Pour éviter les faux positifs, on n’attribue aucun RPPS à ce compte, en comptant sur d’autres règles ou d’autres déclarations pour le rattacher plus tard.
Liens directs entre comptes #
Il s’agit ici non pas d’attribuer un RPPS ou un SIREN à un compte, mais de repérer des comptes que nous avons créés séparément alors qu’ils désignent probablement la même entité (par exemple parce que déclarés par des entreprises différentes). Premier cas : trois comptes bénéficiaires portent le même nom d’association, un seul a un numéro SIREN, les deux autres non. Comme il n’y a aucune incohérence, on considère que ces comptes sont liés ; le SIREN pourra ensuite se propager aux deux comptes qui n’en avaient pas. Deuxième cas : même nom d’association, mais deux comptes ont un SIREN et le troisième n’en a pas ; les deux SIREN sont différents. On ne peut pas savoir lequel attribuer au troisième compte. Comme pour l’ambiguïté sur les RPPS, on ne crée pas de lien entre ces comptes : ils restent distincts pour éviter les faux positifs.
Liens entre associations aux noms différents #
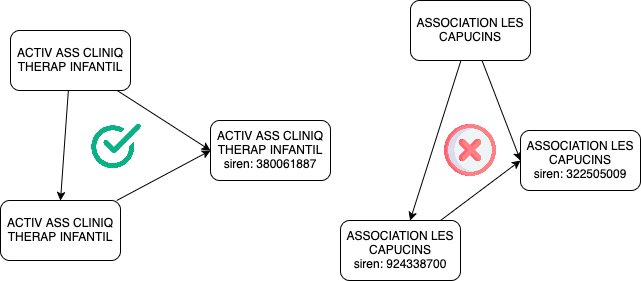
Nous avons vu des cas où le nom d’association matche exactement entre déclarations et entreprises. Souvent, c’est plus complexe : les entreprises déclarent le nom comme elles veulent et produisent de nombreuses variantes pour une même entité. À l’œil humain on reconnaît la même association, mais les distances entre chaînes de caractères (ex. Jaro-Winkler) donnent des résultats très différents. Le matching exact du nom ne s’applique donc pas ; il faut une notion de similarité plus riche.
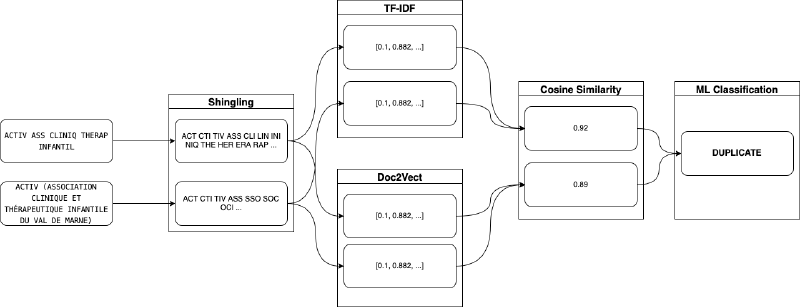
Nous avons mis en place une approche par machine learning. On découpe d’abord chaque nom d’association en trigrammes (ex. « ACTIV » → ACT, CTI, TIV) pour obtenir une liste de tokens. Cela permet d’appliquer ensuite des techniques classiques du NLP pour représenter chaque association par un vecteur. On peut alors obtenir une notion de similarité entre deux associations en comparant leurs vecteurs. On peut alors utiliser plusieurs notions de similarité pour entrainer un modèle de machine learning qui apprendra à différencier les variantes d’une même entité avec de noms d’entités différentes.
Combinaison des règles métier #
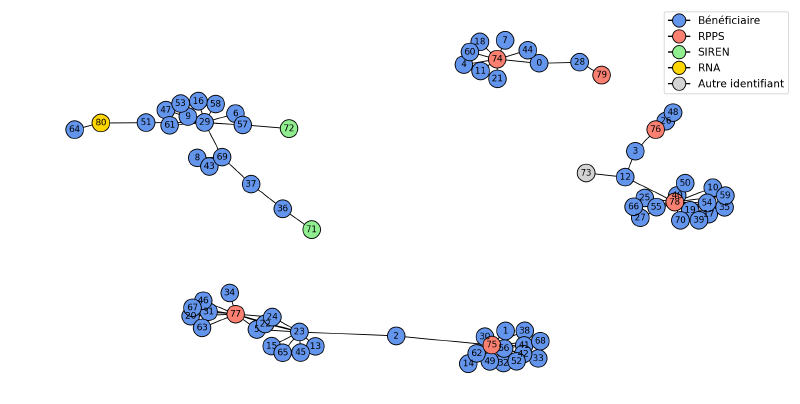
Les étapes précédentes produisent un réseau de liens entre identifiants : liens entre identifiants internes et RPPS, SIREN, RNA, ou liens directs entre comptes internes. On peut représenter tout cela sous forme de graphe (chaque nœud = un identifiant interne, RPPS, SIREN, etc. ; les arêtes = les règles métier qui les relient). On voit ainsi des blocs de comptes liés entre eux de façon plus ou moins directe, séparés du reste. Chaque bloc correspond alors à une entité réelle ; les comptes qu’il contient sont les doublons ou variantes de cette entité dans les déclarations. Certains nœuds n’avaient au départ ni RNA ni SIREN mais ont été rattachés à un bloc grâce à la similarité des noms ou au matching exact. On applique un algorithme de composantes connectées pour regrouper tous les nœuds d’un même bloc, puis on fusionne les informations pour construire une méta-entité avec les données les plus propres issues de tous ces comptes.
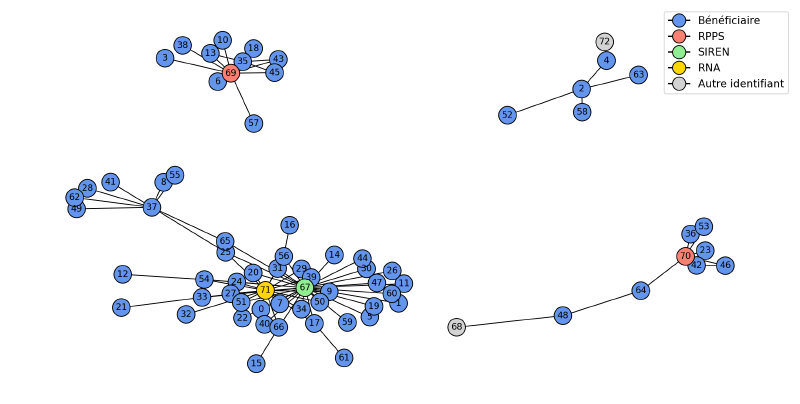
La représentation en graphe sert aussi au contrôle qualité. Certains blocs se structurent autour de plusieurs RPPS ou SIREN, ce qui témoigne d’une incohérence dans certains liens entre nœuds. Ces blocs sont marqués et ne sont pas fusionnés pour ne pas polluer la base finale. Les équipes techniques sont alertées pour analyser les règles en cause et faire évoluer le système.
Les projets disponibles #
Euros for Docs propose actuellement deux projets en collaboration avec des universités pour enrichir les données et mieux comprendre les liens d’influence chez les vétérinaires et les pharmaciens. Transparence Santé fournit surtout des liens directs : laboratoire → pharmacien (personne physique) ou laboratoire → pharmacie (entreprise). Un pharmacien peut recevoir des versements en son nom, via sa pharmacie ou via des associations dont il est membre. Ces relations transversales manquent aujourd’hui pour cartographier les stratégies d’influence multicanal.
Lors d’un séminaire nous avons repéré deux sources : le répertoire des pharmaciens avec leurs caractéristiques et les pharmacies où ils exercent, et un jeu de données sur les vétérinaires et leurs cabinets. L’objectif est de construire un jeu de liens entre bénéficiaires (par exemple lier le RPPS d’un pharmacien au SIREN de sa pharmacie) afin d’obtenir un graphe de réseau plus complet. Chaque projet comportera le traitement et l’historisation d’un jeu de données ouvert, son intégration dans Euros for Docs et du fuzzy matching pour attribuer un SIREN aux cabinets vétérinaires ou aux pharmacies à partir des informations disponibles. Ces données serviront à mettre à jour notre vision du niveau d’influence et des stratégies dans les secteurs pharmaceutique et vétérinaire.
Conclusion #
Data for Good et Euros for Docs illustrent comment mettre la data au service de la transparence et du bien commun. Si vous souhaitez vous investir sur un projet concret (Euros for Docs, Pyronear ou d’autres), rejoignez Data for Good et consultez les projets ouverts aux bénévoles.



