La France compte des centaines de milliers d’associations, de la petite structure locale aux organisations de plusieurs milliers de membres. Pour mener à bien leurs activités, ces associations dépendent souvent de financements publics, notamment des subventions distribuées par les collectivités locales : communes, départements, régions.
Pourtant, cet argent public est dispersé à travers des milliers de collectivités de tailles et budgets différents, ce qui complique le contrôle de la transparence. Si les collectivités ont désormais l’obligation de publier la répartition des subventions qu’elles octroient, cette décentralisation signifie qu’il n’existe aucun système centralisé pour récupérer ces données. Elles se trouvent éparpillées sur le web : sur la plateforme data.gouv.fr, sur les sites des municipalités, parfois sous forme de PDF à télécharger.
À l’approche des élections municipales de 2026, l’association Anticor a souhaité créer un outil centralisé permettant aux citoyens de suivre les subventions octroyées par leurs collectivités et de les comparer avec celles d’autres territoires. Un tel outil permettrait également d’identifier les collectivités qui ne respectent pas leurs obligations de transparence.
Pour réaliser ce projet, les associations Anticor et Transparency International France se sont associées à Data For Good afin de mobiliser des bénévoles. En 3 mois, des experts data bénévoles ont créé la plateforme Éclaireur Public. Ce projet a combiné de la récupération de données, de la normalisation des sources et du développement web pour proposer une cartographie de niveaux de publication.
Sur ce projet, j’ai pris un rôle officieux de tech lead sur la partie d’identification et de normalisation des données. Cet article présente les défis techniques et les solutions développées pour travailler avec ces données ouvertes hétérogènes.
Le projet s’organise autour de trois grandes étapes.
- Identifier sur le web les fichiers de déclarations de subventions publiés par les différentes collectivités.
- Uniformiser tous ces fichiers et les lire pour permettre de créer une base de données commune.
- Exploiter cette base de données pour proposer aux citoyens et utilisateurs de la plateforme non pas des données brutes, mais des statistiques descriptives et des visualisations.
Récupération des données #
Contrairement à d’autres obligations de déclaration comme les rémunérations des médecins pars les laboratoires pharmaceutiques, les données de subventions n’ont pas de plateforme centralisée. Chaque collectivité peut alors choisir de publier à sa manière, avec son propre format. Une des premières difficultés du projet est alors d’identifier où les collectivités qui déclarent déposent leurs documents, pour créer un catalogue de données concernant les subventions.
Plateformes d’open data
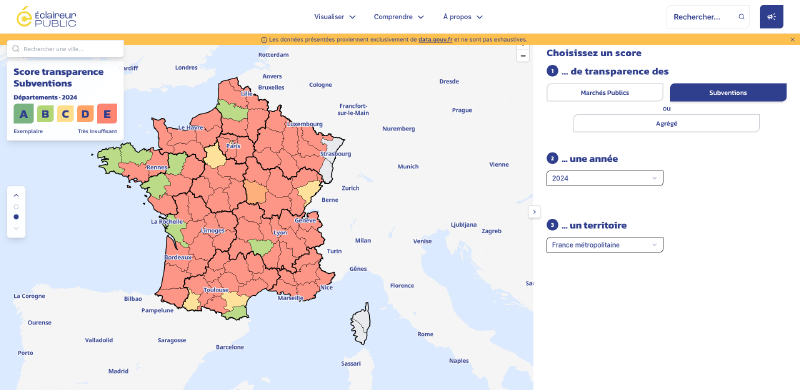
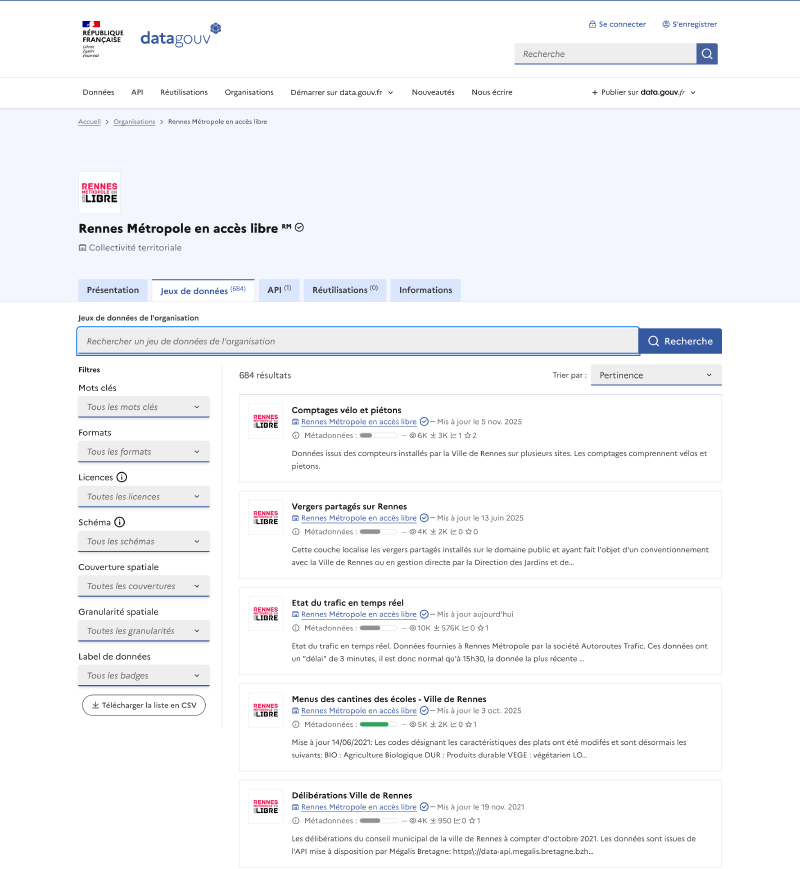
Pour cette première version du projet, l’équipe s’est concentrée sur la plateforme data.gouv.fr qui recense une très grande variété à la fois de jeux de données mais aussi de producteurs de données. Cette plateforme recense des données d’institutions telles que l’État jusqu’à des petites collectivités. Certaines collectivités se permettent d’avoir leur propre plateforme d’open data, tout en maintenant un lien entre data.gouv.fr et leurs propres données. Par exemple, la métropole Rennaise a sa propre plateforme d’open data qui contient bien un fichier de subventions aux associations, mais on retrouve les mêmes données sur data.gouv. En y regardant de plus près l’url de téléchargement du fichier CSV depuis data.gouv pointe en réalité vers la plateforme de la métropole. Ainsi, même si certaines métropoles possèdent leurs propres plateformes, data.gouv reste un point central pour rechercher et collecter des fichiers de subventions.


Le deuxième challenge est alors d’identifier les datasets qui correspondent à des subventions aux associations parmi l’énorme diversité que propose data.gouv. Par exemple, pour rester sur l’exemple de Rennes, le fichier de subvention est déposé aux cotés d’un fichier sur les vergers partagés ou les menus des cantines de la métropole.
Identification des datasets de subvention
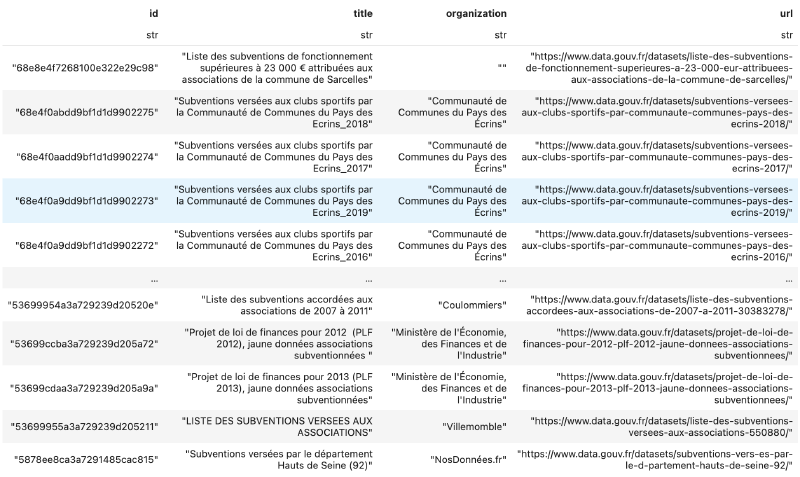
Notre première étape de la pipeline consiste donc à identifier sur data.gouv les jeux de données qui semblent concerner des subventions publiques. data.gouv possède justement un catalogue qui recense l’ensemble de fichiers présents sur la plateforme. Pour chaque fichier, un ensemble de metadonnées sont disponibles telles que le titre, la description ou l’url de téléchargement.
Nous sélectionnons alors les fichiers qui contiennent certains mots clés (tels que subvention) dans leur titre ou leur description.
Cette pré-sélection est assez grossière et va potentiellement cibler des fichiers qui ne correspondent pas aux subventions qui nous intéressent.
Ce sera l’un des rôles de l’étape suivante de normalisation de filtrer ces faux positifs.
Obsolescence des liens
Durant le projet, nous avons fait face à un problème de disponibilité des données. Sans raisons apparentes, les url fournies par le catalogue devenaient obsolètes : les producteurs des données avaient supprimé leurs données. A l’inverse, certains fichiers avaient été modifiés pour ajouter les subventions les plus récentes mais supprimer les plus anciennes. Or, un des objectifs du projet est de proposer un suivi de la qualité des déclarations des collectivités. Nous avons donc besoin de conserver les données. Nous avons alors du mettre en place un système d’historisation des fichiers pour garder trace des changements.
Normalisation des fichiers #
La décentralisation des déclarations pose problème lors de la lecture des fichiers. Chaque collectivité peut publier sa déclaration avec sa propre convention; ce qui nous donne une grande variété de situations à considérer.
L’objectif du projet est de créer une grande base de données unifiée de toutes les subventions de toutes les collectivités. Nous avons donc besoin d’une étape de normalisation des données pour transformer la diversité des fichiers en une convention unique. Au minimum, nous cherchons à identifier et normaliser ces informations essentielles :
- le SIREN de la collectivité,
- le SIREN de l’association,
- le montant de la subvention.
Identification du format #
La première difficulté consiste à identifier le format du fichier lui-même (par exemple excel, csv ou parquet).
data.gouv.fr permet en théorie aux collectivités de le renseigner.
Mais encore une fois le manque de convention génère une grande diversité.
Pour le type de fichier le plus simple, le CSV, on voit dans le champs format des choses comme CSV, csv, fichier plat, voire texte séparé par virgules.
Nous cherchons alors la présence de certaines chaines de caractères pour normaliser ce champs format et faciliter le travail en aval.
Finalement, nous ne pourrons contiuer à traiter ques les fichiers CSV, Excel, JSON et Parquet.

Les collectivités proposent régulièrement le même fichier de subvention en plusieurs formats, généralement CSV et JSON. Notre première recherche par mots-clés dans le catalogue data.gouv sélectionne donc toutes les versions présentes d’un même jeu de données. Nous sommes donc à risque d’intégrer plusieurs fois les mêmes données et surestimer les montants versés par les collectivités. En comparant les titres et descriptions des fichiers nous sommes capables d’identifier des doublons dans des formats différents.
Mais tous les formats de fichiers ne se valent pas en termes de facilité de lecture, en particulier lorsqu’il faut les lire en grand nombre de manière automatique. Comme nous le verrons plus loin, la lecture de fichiers CSV nécessite de connaître plusieurs paramètres que l’on devra deviner. A l’inverse, un fichier de type parquet se lit très facilement. Lorsque nous avons accès à plusieurs format d’un même jeu de données, nous pouvons sélectionner le format le plus pratique pour la lecture.
Lecture des fichiers #
Comme mentionné à la section précédente, tous les formats de fichiers ne présentent pas les mêmes difficultés poaur la lecture. Dans cette section, je présente les formats de fichier que l’on a pu exploiter ainsi que leurs caractéristiques qui facilitent ou compliquent leur exploitation.
Fichiers Parquet
Les fichiers Parquet sont un format normalisé et compressé qui peuvent être lus automatiquement sans traitement particulier. Ils sont en général plus légers que l’équivalent dans d’autres formats, mais sont plutôt réservés aux professionnels de la data car le résultat n’est pas directement lisible dans Excel. Ce format reste assez peu répandu au sein des collectivités.
Fichiers Excel
Les fichiers Excel sont un peu moins standardisés. Nous pouvons facilement extraire chaque élément des données grâce au format Excel, mais nous ne sommes pas assurés que le type de données extrait soit correct. Par exemple, le numéro SIREN d’une collectivité est fondamentalement une chaîne de caractères. Mais pour l’immense majorité des entités qui possèdent un SIREN, celui-ci contient principalement des chiffres et est donc souvent interprété comme un entier. Comme nous connaissons le type des informations que nous recherchons, nous pouvons appliquer une transformation pour formatter correctement les colonnes qui mentionnent un SIREN.
Fichiers CSV
Les fichiers CSV sont les types de fichiers les plus représentés en open data aujourd’hui, mais présentent davantage de difficultés.
La première étape pour lire un CSV est d’identifier l’encodage des caractères, c’est-à-dire la manière dont chaque lettre est encodée par la machine. Le standard le plus utilisé aujourd’hui s’appelle UTF-8 et prend en charge de nombreuses lettres particulières de différents langages. Cependant, les systèmes Windows et l’administration française ont tendance à utiliser un autre standard, plus occidental, ce qui entraîne une impossibilité de lire les fichiers si l’on ne renseigne pas correctement l’encodage utilisé. Dans un système de lecture automatique de CSV, nous n’avons aucun moyen de savoir a priori le standard utilisé. Nous devons donc tester les standards les plus probables et ne garder que celui qui fonctionne.
Dans un fichier CSV, les valeurs des données sont séparées par un caractère conventionnel, historiquement la virgule, d’où le nom du format “comma separated values”. Ce standard a beaucoup évolué et différents types de caractères sont utilisés par différentes collectivités pour séparer les données. On peut retrouver aussi bien des virgules que des points-virgules, des barres verticales ou même des tabulations. Un petit outil dédié nous permet d’analyser les premières lignes du fichier pour identifier ce séparateur.
Fichiers JSON
Le format JSON est le format le plus complexe que nous ayons intégré. Ce format écrit des données en texte brut (comme le CSV) mais, au lieu d’une structure en lignes et colonnes, les informations sont organisées sous forme de clés-valeurs. Les valeurs pouvant également être une collection de clés-valeurs, on se retrouve avec une structure hiérarchique qui diffère dans chaque fichier et crée des difficultés pour identifier les données d’intérêt. Les données de subventions que nous recherchons peuvent être organisées de différentes manières : être mélangées avec des statistiques, des métadonnées ou toute autre information que le producteur de la donnée a souhaité intégrer.
La mairie de Boé que nous avons vu plus haut nous propose le cas le plus simple d’un json.
Le fichier (dont nous ne représentons ici que les premières lignes) ne se compose que de structures réprésentant des déclarations.
Ainsi le premier élément compris entre {} concerce une subvention de 150€ pour une association climatologique.
[
{
"Nom de l'association": "ACMG CLIMATOLOGIQUE",
"Secteur": "SERVICES",
"Montant Subvention": 150
},
{
"Nom de l'association": "ADOT 47",
"Secteur": "SOLIDARITÉ",
"Montant Subvention": 150
},
{
"Nom de l'association": "ALLIANCE 47",
"Secteur": "SOLIDARITÉ",
"Montant Subvention": 200
},
{
"Nom de l'association": "AMICALE LAIQUE DE BOE",
"Secteur": "CULTURE/LOISIRS",
"Montant Subvention": 1300
}
]Pour lire de manière massive ce type de fichier, nous devons faire des hypothèses quant à la structure des fichiers. L’exemple précédent est la manière la plus standard de documenter des subventions. Mais cette structure peut être placée au sein d’autres structures dans le fichier. Notre stratégie est alors de trouver dans le fichier une partie qui contient une grande liste de structures. Lorsque nous trouvons ce schéma, nous considérons que la liste représente l’ensemble des lignes de notre fichier de subvention. Il est donc tout à fait possible d’extraire un élément du fichier qui ne représente pas les subventions mais d’autres informations fournies par la collectivité. C’est l’étape suivante qui nous permettra de détecter ce genre de cas et de potentiellement imposer une extraction plus spécifique pour ce fichier.
Compréhension des colonnes #
Une fois que nous avons extrait les données telles qu’elles ont été saisies par la collectivité, il nous reste à comprendre quelles données ont été publiées et avec quelle convention. En pratique, cela signifie faire correspondre les colonnes du fichier avec la nomenclature que nous avons définie arbitrairement.
Types de données recherchées
Nous distinguons deux niveaux d’intérêt pour les données.
Un ensemble de données sont considérées comme essentielles. Sans elles, on ne peut pas utiliser le fichier pour l’usage le plus simples : représenter le montant versé par collectivité et par année. L’absence d’une de ces informations nous fait rejeter ces informations. Dans cette catégorie on inclue:
- identifiant de la collectivité (nom ou SIREN de préférence),
- identifiant de l’association (SIREN),
- montant versé,
- la date (ou au minimum l’année) de la subvention.
Les informations secondaires représentent des notions qui peuvent enrichir la connaissance sur la subvention mais ne sont pas nécessaires pour nos calculs de scores principaux. Ces informations sont par exemple la description de l’association, la répartition des montants ou différentes dates de versement.
Compréhension des colonnes
Chaque collectivité va avoir sa propre convention pour désigner les différents concepts.
Par exemple, dans l’exemple précédent de la mairie de Boé, le champ Nom de l'association identifie le bénéficiaire de la subvention par le nom commun.
Une autre collectivité pourrait nommer la même information nom_association ou Nom du bénéficiaire.
Nous devons donc tenter de comprendre les différentes logiques utilisées par les collectivités et trouver les mots clés qui nous permettent d’identifier les concepts que l’on recherche.
Ce mécanisme présente toutefois des limites.
Quelquefois, le titre de la colonne peut correspondre à plusieurs concept.
Nous devons alors faire un choix, parfois arbitraire.
Parfois, l’analyse du contenu de la colonne peut aidier; en identifiant par exemple si une colonne association contient un nom pour un SIREN.
Recherche dans les métadonnées
Si nous n’arrivons pas à trouver certaines informations dans le fichier (telles qu’une date ou le nom de la collectivité), nous allons analyser le titre et la description du fichier pour tenter de les retrouver puis de les ajouter au fichier. Toujours dans notre exemple précédent, les informations fournies sur les subventions sont minimalistes : le nom de l’association et le montant. C’est donc à travers le nom de l’organisation déclarante que nous pouvons obtenir le nom de la collectivité et par le nom du fichier que nous pouvons obtenir, au minimum, l’année de la subvention.
Normalisation des valeurs #
La dernière étape de notre traitement de fichiers consiste à normaliser les données. Même une notion aussi simple qu’un montant de subvention peut apparaitre sous de multiples formes.
Montant
Dans une situation idéale, le montant de la subvention est directement interprété comme un nombre dès la lecture du fichier source. Cependant, comme la France utilise la virgule pour séparer les décimales (contrairement aux pays anglophones qui utilisent le point), donc un nombre à virgule sera souvent interprété comme une simple chaîne de caractères. Des espaces peuvent aussi être présents pour séparer les milliers et le signe euro peut également être présent. Nous appliquons donc une série de nettoyages sur les chaînes de caractères représentant les montants pour pouvoir les interpréter comme des nombres. Nous nous assurons que les chaînes de caractères suivantes (“1,500 €”, “2 500 euros”, “3,500.00”) sont bien interprétées comme respectivement (1500, 2500, 3500).
Identifiant
La manière la plus fiable d’identifier une collectivité ou une association est l’utilisation du numéro SIREN. Ce numéro a deux variantes souvent utilisées de manière interchangeable.
Le numéro SIREN est lié à l’entité juridique et une chaines de caractères (presque exclusivement des chiffres) à 9 éléments. Lorsque l’identifiant ne contient pas de lettre, il est souvent interprété comme un entier. Les zéros initiaux peuvent alors disparaître.
Le numéro SIRET est aussi régulièrement utilisé en lieu et place du SIREN. Ce numéro fait référence à chacun des lieux physiques que possède une entité. Il se compose de 15 caractères dont les 9 premiers correspondent au numéro SIREN.
Nous avons choisi arbitrairement de normaliser les identifiants vers le numéro SIREN. À travers une série de vérifications du nombre de caractères et d’ajout de zéros manquants, nous pouvons nettoyer et normaliser les colonnes d’identifiant.
Noms des entités
Les noms des entités (collectivités ou associations) sont parmi les données les plus hétérogènes que nous traitons. En effet, deux collectivités n’écrirons pas de la même manière le nom d’une même association. Cet article détaille cette problématique sur un autre projet. Afin de faciliter la recherche de l’ensemble des subventions d’une collectivité ou association pour nos utilisateurs, notre objectif est de fusionner ces différentes variantes en un même nom.
L’exemple de la mairie de Boé illustre un cas particulier : la collectivité ne fournit aucun identifiant, que ce soit pour elle-même ou pour les associations bénéficiaires. Il existe sur data.gouv.fr un fichier qui permet de relier l’identifiant data.gouv de la collectivité avec son SIREN. Ce fichier avait été créé suite à une étude pour évaluer le degré d’appropriation de l’open data par les collectivités. Ce fichier peut alors nous permettre de retrouver le siren de la collectivité (et donc son nom). Notre exploration des collectivités sur data.gouv nous a même permis de mettre à jour ce fichier.
En revanche, il est plus difficile d’attribuer un SIREN à une association en ne se basant que sur son nom. Il faudrait mettre au point une analyse comparative entre le nom documenté et les noms officiels. En l’état, le projet n’a pas ce type de mécanisme. Si une association est nommée de deux manière différentes par deux collectivités et qu’aucun SIREN n’est fourni, les deux variantes vont rester sous forme de doublon dans la base finale.
Gestion des erreurs #
Tout le processus de normalisation des fichiers que nous venons de décrire repose sur plusieurs étapes empiriques basées sur des exemples. Il est donc courant de rencontrer des fichiers qui proposent de nouveaux cas particuliers : nouveaux séparateurs pour les CSV ou nouveaux mots-clés à extraire pour identifier le sens d’une colonne.
Un des objectifs du projet est d’arriver à traiter un maximum de fichiers malgré la diversité. Nous avons donc mis au point un système qui organise les fichiers que nous n’arrivons pas à traiter en fonction du type d’erreur. Par exemple, nous listons les fichiers pour lesquels le téléchargement a échoué séparément de ceux pour lesquels le fichier CSV semble ne pas avoir de nom de colonne.
Cette compilation d’erreurs, qui représente plus d’une centaine de fichiers, sert de guide pour orienter les futures améliorations du projet.
Types d’erreurs rencontrées
Les erreurs les plus fréquentes sont les suivantes :
-
Des colonnes d’identifiant avec un nom très particulier qui ne sont pas détectées par les dictionnaires de mots-clés. Ces cas nécessitent une analyse manuelle pour identifier le pattern et l’ajouter au dictionnaire.
-
Des fichiers dont le format n’est pas pris en compte par notre pipeline : principalement des fichiers PDF et HTML. Ces formats nécessitent des traitements spécifiques que nous n’avons pas encore intégrés.
-
Des fichiers CSV ou Excel qui n’ont pas de nom de colonnes et dont nous ne pouvons pas identifier le sens des colonnes individuelles. Sans noms de colonnes, il est difficile de faire le mapping avec notre nomenclature.
-
Des fichiers qui sont des archives zippées mais dont le format déclaré n’est pas ZIP mais le format du fichier à l’intérieur de l’archive (CSV par exemple). Notre système tente alors de lire directement le fichier comme un CSV, ce qui échoue car il s’agit en réalité d’une archive.
Pipeline d’enrichissement #
Les déclarations de subventions forment le cœur du projet Éclaireur Public et représentent les données les plus complexes à collecter. Cependant, data.gouv.fr contient d’autres données qui permettent d’enrichir les analyses que l’on peut effectuer sur les collectivités.
Données de marchés publics
En plus des subventions, nous avons également accès en ligne aux données sur les attributions de marchés publics. Ces données ont l’avantage d’avoir été centralisées et uniformisées, ce qui permet de les intégrer aux analyses via le téléchargement d’un unique fichier. Ce fichier est fourni au format JSON avec une structure hiérarchique complexe. Comme toute l’information est contenue dans un seul fichier, il est possible de créer un code spécifique et rigoureux pour ce format.
Données financières
L’open data nous permet également d’obtenir les derniers comptes de résultats des différentes collectivités. À travers quatre fichiers (ville, communauté de communes, département, région), nous pouvons comparer les subventions aux autres indicateurs financiers des collectivités et créer des métriques qui permettent de regrouper les collectivités en groupes comparables.
Données sur les élus
Les porteurs du projet étant des associations de lutte contre la corruption et les conflits d’intérêt, le projet a également inclus des données sur les élus des différentes collectivités ainsi que leurs déclarations d’intérêt. Ces données permettent de croiser les informations sur les subventions avec les déclarations d’intérêt des élus.
Système de scoring
À partir de toutes les informations que nous avons regroupées sur les collectivités, nous pouvons les évaluer sur plusieurs aspects de leur transparence.
Le score de transparence des subventions évalue la cohérence entre les subventions effectivement déclarées dans les bases de données publiques et les subventions budgétées dans les comptes financiers officiels. Un taux proche de 100% indique une bonne correspondance entre ce qui est déclaré et ce qui est budgété. Un taux trop faible suggère une sous-déclaration, voire une non-déclaration, tandis qu’un taux trop élevé peut indiquer un problème de comptage ou de traitement de notre part. Ce score permet d’identifier les collectivités qui respectent leurs obligations de transparence et celles qui ont des écarts significatifs.
Le score de qualité des marchés publics évalue la qualité et la complétude des données publiées. Il prend en compte plusieurs critères progressifs : la présence de données, leur complétude (montant, dates, lieux, procédures, etc.) et le respect des délais de publication.
Conclusion #
Le projet Éclaireur Public illustre les défis techniques que pose le travail avec des données ouvertes hétérogènes. L’absence de normalisation dans la publication des subventions par les collectivités crée une diversité de formats, de conventions et de structures qui complique leur traitement automatique.
La pipeline développée permet de traiter une majorité des fichiers identifiés sur data.gouv.fr grâce à une approche itérative basée sur des règles empiriques. Les étapes de normalisation, de mapping des colonnes et de gestion des erreurs permettent d’unifier progressivement des données disparates en une base commune exploitable.
L’enrichissement avec d’autres sources de données ouvertes (marchés publics, comptes financiers, données sur les élus) permet d’évaluer la transparence des collectivités selon plusieurs dimensions. Les scores développés offrent aux citoyens un moyen de comparer les pratiques de transparence entre collectivités et d’identifier celles qui respectent leurs obligations.
Le projet reste en évolution continue. Les fichiers non traités servent de guide pour améliorer la pipeline et étendre progressivement la couverture des collectivités. Cette approche itérative est nécessaire face à la diversité des pratiques de publication, qui évolue au fil du temps.
Pour les data scientists qui travaillent avec des données ouvertes, ce projet montre l’importance de prévoir des mécanismes robustes de gestion des erreurs et d’itération sur les cas limites. La normalisation de données hétérogènes nécessite souvent des solutions empiriques adaptées à chaque contexte, plutôt que des approches standardisées.



