Introduction #
L’association Data For Good développe depuis 2015 des outils numériques pour des associations et ONG. Chaque année, des dizaines de projets voient le jour grâce à la collaboration entre des bénévoles experts de la tech et des organisations à impact social ou environnemental.
Ces projets couvrent des domaines variés : surveillance de la pêche industrielle, détection de désinformation climatique, transparence dans la santé, ou encore lutte contre les inégalités. L’association rassemble une communauté de 6000 bénévoles experts en data et IA.
Cependant, les profils juniors en data science rencontrent des difficultés pour participer efficacement à ces projets. Bien qu’ils possèdent souvent des compétences techniques de base (SQL, Python), il leur manque souvent des compétences de base en développement logiciel pour contribuer de manière autonome dans un environnement professionnel.
Cet article est à destination des juniors qui pourraient se sentir concernés par cet angle mort dans leurs compétences. Il présente le programme Warmup Junior, un parcours d’apprentissage conçu spécifiquement pour les profils juniors afin d’acquérir ces compétences collaboratives en contribuant à un projet open source professionnel.
Qu’est-ce que le programme Warmup Junior ? #
Le constat #
Les profils juniors constituent une majorité des participants aux saisons Data For Good, qu’ils viennent d’une formation initiale ou d’une reconversion professionnelle. Pourtant, la plupart des formations en data science se concentrent sur les compétences analytiques (SQL, Python, statistiques) et négligent les compétences de base en développement nécessaires pour travailler dans un projet collaboratif.
En pratique, lorsqu’un junior rejoint un projet open source, il rencontre rapidement trois difficultés principales :
- L’utilisation de Git et GitHub : créer une branche, gérer les commits, comprendre l’historique du projet sont des opérations nouvelles pour beaucoup.
- Le processus de code review : soumettre son code pour validation, comprendre les commentaires et intégrer les retours demande une familiarité avec ces pratiques.
- La qualité du code : écrire du code qui fonctionne n’est pas suffisant; il faut aussi qu’il soit lisible, bien structuré et facile à maintenir pour les futurs contributeurs.
Dans le contexte des saisons Data For Good, ces difficultés sont encore plus marquées. Un projet compte en moyenne seulement deux seniors data bénévoles, qui doivent à la fois développer et accompagner les juniors. Or, les projets de saison sont intenses, avec des deadlines serrées, et le contexte de bénévolat entraîne souvent une rotation importante des contributeurs. Dans ces conditions, il devient difficile pour un senior de prendre le temps d’expliquer les bases à un junior qui découvre ces outils pour la première fois.
La solution proposée #
Le programme Warmup Junior propose d’accompagner les bénévoles juniors pour les rendre opérationnels sur un projet collaboratif. À noter : ce programme n’est pas une formation en data science. C’est un accompagnement aux bonnes pratiques de l’ingénierie logicielle. Son objectif est concret : corriger un bug simple et faire en sorte que cette correction soit intégrée dans le projet.
Le programme s’appuie sur un projet mature qui fonctionne hors saison. Un projet mature signifie que les standards de développement sont déjà en place : tests unitaires, code review, conventions de nommage, documentation. En travaillant sur ce type de projet, vous découvrez directement ces pratiques professionnelles et vous apprenez à y contribuer selon ces règles.
Les projets hors saison présentent plusieurs avantages pour l’apprentissage. Ils ne sont pas soumis aux deadlines serrées des saisons, ce qui signifie qu’une contribution peut prendre plusieurs semaines ou plusieurs mois sans poser de problème. Vous avez donc le temps de comprendre chaque concept à votre rythme, de tester, d’échouer et de réessayer. Les seniors qui maintiennent ces projets ont également plus de disponibilité pour répondre à vos questions et vous guider dans les bonnes pratiques.
Le programme fonctionne principalement en autonomie : vous disposez d’un parcours d’étapes à suivre, avec des ressources sélectionnées pour comprendre chaque notion. Un mentor bénévole est disponible en asynchrone via la messagerie Data For Good pour répondre à vos questions et vous aider à débloquer une situation si nécessaire.
La suite de cet article détaille les étapes du programme dans le cadre d’une contribution aux projets hors saison Euros For Docs.
Participer au programme #
Le projet EurosForDocs #
Avant de commencer à contribuer, il est important de comprendre le contexte et les objectifs du projet. Cette compréhension vous permet de vous faire une idée de l’organisation générale du projet, et cette organisation se reflète généralement dans la structure du code. Par exemple, si un projet gère différents types de données (professionnels de santé, laboratoires, rémunérations), vous trouverez probablement ces concepts séparés dans le code.
Euros For Docs est un projet qui existe depuis 2018 et qui a subi une refonte complète en 2023. Cette longue histoire et cette récente modernisation en font un projet mature et stable. Tous les standards de développement professionnel sont déjà en place : architecture structurée, tests unitaires, processus de review, outils d’automatisation. C’est précisément cette maturité qui en fait un terrain d’apprentissage idéal : vous découvrirez directement les pratiques utilisées dans les projets professionnels.
Le projet vise à améliorer la transparence dans le domaine de la santé. Depuis 2014, les laboratoires pharmaceutiques ont l’obligation de déclarer toute rémunération versée aux professionnels de santé (médecins, pharmaciens, etc.). Ces déclarations sont publiques et disponibles sur une base de données open data. Cependant, cette base de données est difficile à exploiter : les données sont brutes, mal structurées et il n’existe pas d’interface utilisateur pour les consulter facilement.
Le projet développe une pipeline de données qui s’exécute quotidiennement et qui réalise trois actions principales :
- Téléchargement : récupère automatiquement les données brutes depuis le site officiel.
- Nettoyage et structuration : traite ces données pour améliorer leur qualité et les rendre exploitables.
- Publication : met à jour le site web avec une interface publique permettant de rechercher et d’analyser les rémunérations.
Pour approfondir la compréhension du projet avant de contribuer, plusieurs ressources sont disponibles :
- Vision d’ensemble de la pipeline de données : présentation générale du fonctionnement du projet
- L’étude de cas ACTIV : exemple concret montrant la difficulté d’identifier correctement les bénéficiaires de rémunérations
- Méthode de déduplication des bénéficiaires : explication technique d’un des problèmes data principaux du projet
Installation et exécution du projet #
Téléchargement du projet #
Le code source du projet Euros For Docs est public et accessible sur GitLab. Si vous n’êtes pas familier avec l’utilisation de GitLab (ou GitHub), il est conseillé de suivre ce MOOC de 2h créé par le pôle formation de Data For Good. Tous les concepts abordés dans ce mooc seront utiles dans la suite du programme.
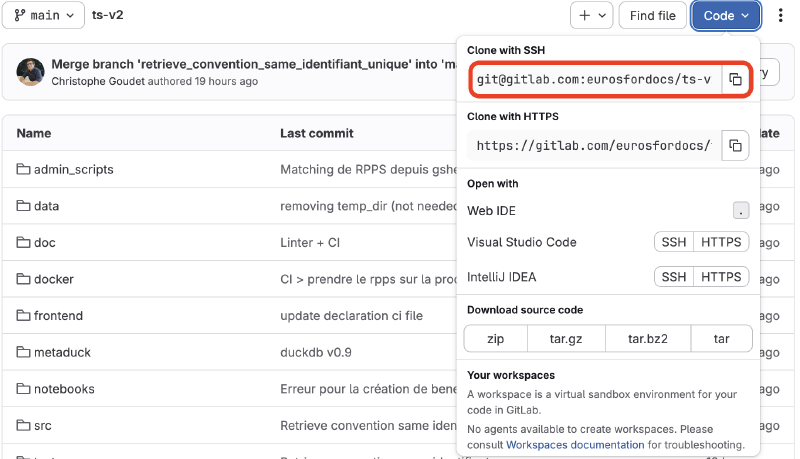
Avant de pouvoir contribuer, vous devez télécharger le projet sur votre machine et l’installer. Depuis la page du projet, vous pouvez obtenir l’URL pour télécharger le projet sur votre machine. Dans un terminal, placez vous dans le dossier dans lequel vous voulez télécharger le projet et lancez la commande suivante.
git clone git@gitlab.com:eurosfordocs/ts-v2.gitCelle-ci va télécharger l’intégralité du projet sur votre machine. À partir de maintenant, vous pouvez modifier à volonté le code sur la machine sans que cela n’impacte le projet pour les autres contributeurs. Les prochaines étapes expliqueront comment partager vos modifications.
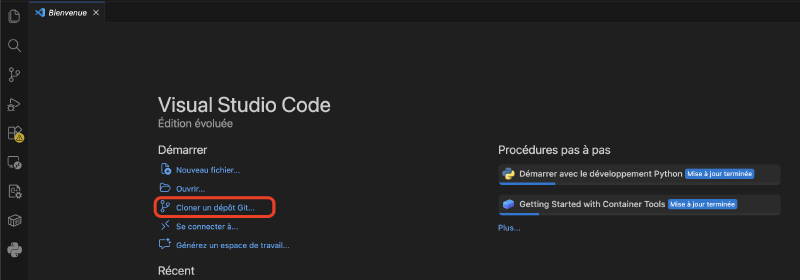
Une manière alternative de télécharger le projet est d’ouvrir directement votre éditeur de code. Tous les éditeurs modernes ont une interface pour ouvrir un projet à partir d’une URL. Par exemple, la page d’accueil de VSCode propose justement l’option de cloner un dépôt Git.
Création d’une clé SSH #
Les plateformes collaboratives telles que GitLab ont la notion de droits attribués aux utilisateurs. Il est donc essentiel que les utilisateurs soient authentifiés avant toute modification. Une des méthodes les plus pratiques et sûres pour s’authentifier sans avoir à taper un mot de passe à chaque interaction avec le site web est l’utilisation de clés SSH. Ces clés sont un moyen de dire à GitLab que cet ordinateur appartient à un compte utilisateur particulier et donc d’être automatiquement authentifié.
Pour mettre en place ce système, vous devez créer une clé sur votre ordinateur et la renseigner dans vos paramètres utilisateurs sur GitLab. La documentation de GitLab vous propose un tutoriel pour créer et configurer vos clés : https://docs.gitlab.com/user/ssh/. Cette étape peut prendre un peu de temps la première fois le temps de comprendre les concepts.
Cette étape n’a pas besoin d’être répétée pour contribuer sur d’autres projet sur GitLab. Par contre il faudra reconfigurer de nouvelles clés si vous changez d’ordinateur ou si vous contribuez à un projet hébergé sur une autre plateforme (GitHub par exemple).
Installation de l’environnement #
Pour faire fonctionner le projet sur sa machine, il faut installer toutes les dépendances du projet.
Tous les projets matures contiennent un fichier nommé README.md à la base du projet.
Ce fichier contenant du texte formaté est en particulier affiché en bas de la page d’accueil du projet sur GitLab.
C’est dans celui-ci que vous trouverez les instructions d’installation spécifiques à ce projet.
Le projet EurosForDocs est un projet assez simple en termes de technologie, l’essentiel est fait en python.
De plus toutes les étapes d’installation sont regroupées dans une seule commande make install.
Cette commande va en déclencher deux autres :
- la création d’un environnement virtuel python,
- l’installation des librairies nécessaires (documentées dans
requirements.txt) dans cet environnement.
Un environnement virtuel est un moyen d’isoler l’installation des librairies d’un projet spécifique. Ainsi, si vous travaillez sur deux projets qui ont besoin d’une même librairie dans deux versions distinctes, chaque projet aura sa propre version indépendamment de comment évolue l’autre. Même si les détails de cette partie sont cachés sur EurosForDocs, il est recommandé aux personnes non familières avec cette notion de se former à ce concept. Cette vidéo de 10min est un bon point de départ pour aborder cette notion.
Configurer les variables d’environnement #
Tous les projets informatiques nécessitent l’utilisation d’informations que l’on ne souhaite pas divulguer au grand public. Par exemple, si le projet nécessite de se connecter à une base de données, on n’a pas envie de mettre directement dans le code l’adresse et le mot de passe d’accès à la base. À la place, on va intégrer dans le code des variables spécifiques : les variables d’environnement. Ainsi, lorsque le code aura besoin de la valeur de ces variables, il va demander à la machine qui l’héberge la valeur à utiliser.
Cela implique par contre que chaque machine qui souhaite utiliser le code ait accès à cette information. Pour cela, la convention est d’avoir un fichier texte dans le projet qui va contenir la liste de ces variables d’environnement ainsi que leur valeur à utiliser. Cette méthode permet aussi d’avoir des comportements différents du code : par exemple, en changeant les valeurs des variables d’environnement on peut aller requêter une base de test que l’on peut se permettre de casser au lieu de requêter la base de production beaucoup plus sensible. Cette vidéo de 5min aborde les étapes essentielles pour comprendre ce concept.
Par exemple, le projet EurosForDocs conseille de vérifier le fonctionnement de la pipeline avec une version allégée grâce à ces paramètres.
# .env
ENVIRONMENT="CI"
DUCKDB_MEMORY_LIMIT=8GExécution du projet #
Une fois l’ensemble des librairies installées et l’environnement configuré, on peut exécuter le projet pour vérifier que tout fonctionne correctement.
Les instructions spécifiques pour lancer un projet sont documentées dans le README.md et peuvent être très différentes selon le type de projet (site web, pipeline, …) et les choix de technologie et d’infrastructure.
Dans le cas particulier d’EurosForDocs, nous ne nous intéressons qu’à faire tourner la pipeline de traitement des données et en particulier la pipeline allégée de test.
Encore une fois dans ce projet, une seule commande (make process) lance l’intégralité du traitement.
Résolution d’un ticket #
Obtenir un ticket #
Une fois l’installation réussie et la pipeline fonctionnelle, contactez le chef de projet pour obtenir un ticket d’amélioration. Un ticket décrit une tâche à réaliser : il peut s’agir de corriger un bug, d’optimiser une partie du code, ou d’ajouter une petite fonctionnalité. Ce ticket vous donne un objectif concret et vous guide vers une partie spécifique du code à comprendre et à modifier.
Comprendre l’architecture #
Prenez le temps d’explorer la structure du code. Regardez comment les différents modules sont organisés, quels fichiers contiennent quelles fonctions, comment les données circulent entre les différentes étapes. Cette exploration vous aidera plus tard à localiser rapidement la partie du code concernée par votre contribution.
Création d’une Pull Request #
Dans un projet collaboratif, on ne modifie jamais directement le code principal du projet. Chaque contributeur travaille sur sa propre copie du code (appelée une “branche”) pour résoudre son ticket. Une fois la solution implémentée et testée localement, cette copie est proposée pour intégration dans le projet principal via une Pull Request (ou “Merge Request” sur GitLab).
Qu’est-ce qu’une Pull Request ?
Une Pull Request est une demande de fusion de votre code dans le projet principal. Elle permet de soumettre votre travail à une review (relecture) par d’autres contributeurs, généralement des seniors du projet.
Pourquoi passer par une review ?
La review a plusieurs objectifs :
- Vérifier que votre code résout correctement le problème posé par le ticket
- S’assurer que le code s’intègre bien avec le reste du projet (logique cohérente, pas de régression)
- Améliorer la qualité du code en suggérant des améliorations (lisibilité, performance, meilleures pratiques)
C’est un processus d’apprentissage : les commentaires des reviewers vous aident à progresser et à comprendre les standards du projet. Cet article présente l’intérêt de la review dans un projet collaboratif.
Comment créer une Pull Request ?
Le pôle formation de Data for Good propose un MOOC rapide qui explique pas à pas comment préparer et proposer une pull request : lien vers le MOOC
Tests unitaires #
Lorsque vous écrivez du code, vous vérifiez évidemment qu’il résout le problème posé. Vous pouvez même tester différents cas particuliers pour vous assurer de sa robustesse. Cependant, quand vous quittez le projet, la personne qui reprendra votre code ne saura pas forcément quel était le rôle exact de ce code ni tous les cas particuliers qu’il est censé traiter.
Pourquoi écrire des tests ?
Les tests unitaires sont des petits programmes qui vérifient automatiquement que vos fonctions se comportent comme prévu. Ils exécutent vos fonctions avec des arguments connus et vérifient que les résultats obtenus correspondent aux résultats attendus.
L’intérêt principal : si quelqu’un modifie votre code plus tard (par exemple pour corriger un bug ou ajouter une fonctionnalité), les tests vont détecter automatiquement si ce changement casse quelque chose de manière inattendue. C’est une sécurité qui protège le projet contre les régressions.
Cette vidéo introduit le concept de tests unitaires pour la data science.
Tests dans le projet Euros For Docs
Les projets matures comme Euros For Docs contiennent déjà de nombreux tests unitaires. Vous pouvez voir un exemple concret dans le fichier test_clean_functions.py qui teste les fonctions de nettoyage des données.
Intégrer les tests dans votre contribution
Quand vous contribuez au projet, vous devez prendre en compte les tests existants :
- Pour corriger un bug : mettez à jour les tests pour vérifier que le bug est bien résolu
- Pour ajouter une fonctionnalité : ajoutez de nouveaux tests qui vérifient le comportement de votre nouvelle fonctionnalité
- Pour optimiser du code : assurez-vous que tous les tests passent toujours, garantissant que votre optimisation n’a pas cassé le comportement existant
Qualité du code #
Résoudre un problème technique n’est qu’une partie du travail. Votre code doit également être facile à comprendre et à modifier pour les futurs contributeurs qui devront le maintenir ou l’améliorer.
Pourquoi la qualité du code est importante ?
Le code que vous écrivez aujourd’hui sera lu, modifié et débogué par d’autres personnes (ou par vous-même dans quelques mois). Un code de qualité réduit le temps nécessaire pour comprendre ce qu’il fait et limite les risques d’introduire des bugs lors de modifications futures.
Les principes de base
Deux aspects principaux déterminent la qualité d’un code :
- La lisibilité : des noms de variables et de fonctions clairs et explicites permettent de comprendre rapidement le rôle de chaque élément sans avoir à déchiffrer la logique ligne par ligne
- La structure : une organisation cohérente du code facilite la navigation entre les différents modules et permet de localiser rapidement la partie concernée par une modification
Apprendre les bonnes pratiques
Ces concepts peuvent sembler abstraits au début. Sachez qu’une part importante de la code review consiste justement à proposer des suggestions pour améliorer la qualité de votre code. C’est un processus d’apprentissage : chaque review vous fait progresser.
Cette vidéo propose une première introduction aux bonnes pratiques de développement. Il est important de comprendre que ces pratiques ne sont pas des règles absolues mais plutôt un état d’esprit à adopter progressivement. Personne ne s’attend à ce qu’un junior produise du code de qualité professionnelle dès le premier essai. L’objectif est plutôt de prendre conscience de ces concepts et de chercher à les appliquer régulièrement. Avec l’expérience et les retours des reviews, vous progresserez naturellement.
Pre-commit hooks #
Les pre-commit hooks sont des vérifications automatiques qui s’exécutent avant que vous n’enregistriez votre code (commit) dans Git. Leur rôle est de s’assurer que votre code respecte les conventions de style et de qualité définies par le projet.
Pourquoi utiliser des pre-commit hooks ?
Sans ces outils, chaque contributeur pourrait avoir son propre style de code : des espaces différents, des longueurs de lignes variables, des imports non triés, etc. Résultat : le code devient difficile à lire et à maintenir, même si techniquement il fonctionne. Les pre-commit hooks garantissent une cohérence automatique du style sur l’ensemble du projet.
Comment ça fonctionne ?
Lorsque vous tentez de faire un commit, les hooks vérifient automatiquement votre code. S’ils détectent des problèmes de style, le commit est bloqué et vous recevez des instructions pour corriger les erreurs. Une fois les corrections apportées, vous pouvez refaire votre commit qui sera accepté.
Les outils utilisés : Ruff
Le projet Euros For Docs utilise notamment Ruff, un outil Python moderne qui vérifie et corrige automatiquement le style du code. Ruff est rapide et combine les fonctionnalités de plusieurs outils classiques (linters, formatters) en un seul outil.
Configurer son IDE pour auto-formater
Pour éviter d’avoir à corriger manuellement à chaque commit, vous pouvez configurer votre IDE (VS Code, PyCharm, etc.) pour qu’il formate automatiquement votre code selon les mêmes règles que Ruff.
- Dans VS Code : installez l’extension “Ruff” qui formate automatiquement votre code à la sauvegarde
- Dans PyCharm : configurez Ruff comme formateur externe dans les paramètres
Ainsi, votre code sera déjà formaté correctement avant même de faire votre commit, et les pre-commit hooks passeront sans problème. C’est plus efficace et vous évite des allers-retours frustrants.
Intégration continue (CI) #
L’intégration continue (CI) est un système automatique qui vérifie votre code à chaque fois que vous poussez (push) vos modifications sur GitLab. Même si les pre-commit hooks ont vérifié votre code localement, la CI effectue une double vérification sur un environnement propre, identique pour tous les contributeurs.
Que vérifie la CI ?
La CI exécute automatiquement plusieurs vérifications sur votre Pull Request :
- Les tests unitaires : tous les tests du projet sont exécutés pour s’assurer que votre contribution n’a pas cassé le comportement existant
- Le style du code : les mêmes vérifications que les pre-commit hooks sont relancées (formatage, conventions, etc.)
- D’autres vérifications spécifiques au projet : selon les projets, la CI peut aussi vérifier la documentation, la couverture de tests, ou d’autres critères de qualité
Pourquoi c’est important ?
La CI garantit que tous les contributeurs travaillent selon les mêmes standards, même s’ils ont des configurations locales différentes. C’est une sécurité supplémentaire qui protège la qualité du projet principal.
Comprendre les résultats de la CI
Après avoir créé votre Pull Request, la CI se déclenche automatiquement. Sur la page GitLab de votre PR, vous verrez le statut de la CI :

- Si tous les checks sont verts ✅ : votre code respecte les standards et peut être fusionné
- Si un check est rouge ❌ : la CI a détecté un problème (test qui échoue, problème de style, etc.)
En cas d’échec, l’interface GitLab vous indique précisément quel test a échoué ou quelle vérification de style a été détectée, vous permettant de corriger le problème avant de demander une nouvelle review.
Conclusion #
Le programme Warmup Junior propose un parcours pratique pour les data analysts débutants qui souhaitent contribuer aux projets Data For Good. En s’appuyant sur un projet stable hors saison comme Euros For Docs, il permet d’acquérir progressivement les compétences collaboratives nécessaires pour travailler efficacement dans un environnement professionnel.
Ce que vous aurez appris
À l’issue du programme, vous maîtriserez les bases du développement collaboratif :
- La gestion de projet avec Git et les Pull Requests
- L’écriture et la maintenance de tests unitaires
- Les standards de qualité de code et leur importance
- Les outils d’automatisation (pre-commit hooks, CI) qui garantissent la cohérence du projet
Ces compétences vous permettront de contribuer de manière plus autonome aux projets de saison Data For Good, où vous pourrez vous concentrer sur les aspects data plutôt que sur la prise en main des outils.
Se lancer dans le programme
Pour participer au programme Warmup Junior :
- Se connecter au Slack Data For Good et se présenter sur le canal
#6_eurosfordocs. - Installer l’environnement du projet en suivant le README.
- Faire valider votre installation et obtenir un premier ticket.
- Suivre les étapes décrites dans cet article : correction du bug, tests, Pull Request, intégration des retours.
Le programme se déroule à votre rythme, avec l’accompagnement d’un mentor disponible en asynchrone pour répondre à vos questions.
Au-delà du programme
Une fois votre première contribution réussie, vous pouvez continuer à contribuer au projet hors saison ou passer aux projets de saison. Les compétences acquises sont transférables à d’autres projets open source, professionnels ou personnels.
Le programme Warmup Junior constitue ainsi un premier pas concret vers une contribution autonome et efficace dans l’écosystème Data For Good.